Nghiên cứu dùng AI phát triển pin mới được tối ưu hoá
 Google Dịch chính thức rút lui khỏi thị trường Trung Quốc
Google Dịch chính thức rút lui khỏi thị trường Trung Quốc Top đồng hồ thông minh dưới 1 triệu đáng mua nhất hiện nay
Top đồng hồ thông minh dưới 1 triệu đáng mua nhất hiện nayMột nhóm các nhà nghiên cứu tại Đại học Carnegie Mellon đã phát triển một cách tiếp cận mới để đẩy nhanh quá trình tạo ra các loại pin được tối ưu hóa hơn bao giờ hết.
Trong bài báo đăng trên tạp chí Nature Communications, nhóm mô tả cách họ ghép nối một loại robot độc đáo với hệ thống học tập dùng trí tuệ nhân tạo AI để tạo ra chất điện phân lỏng không chứa nước hữu ích hơn bao giờ hết.
Khi doanh số bán các thiết bị cầm tay tăng vọt và các nhà sản xuất ô tô đã chuyển sang dùng xe điện, nhu cầu về pin sử dụng được lâu hơn và sạc nhanh hơn cũng tăng lên. Thật không may, khoa học phát triển pin mới để phục vụ những nhu cầu như vậy đã bị tụt hậu – nó thường liên quan đến việc sử dụng trực giác của các nhà hóa học cùng với sự bền bỉ. Những nỗ lực như vậy có thể mất nhiều năm. Trong nghiên cứu mới này, các nhà nghiên cứu ở Pittsburgh đã tìm cách tăng tốc quá trình bằng cách sử dụng các kỹ thuật tự động hóa.
Trọng tâm của hầu hết các thiết kế pin là việc tạo ra chất điện phân pin lithium-ion không chứa nước hoạt động tốt hơn so với những loại pin đã được phát triển trước đó. Các nhà nghiên cứu có xu hướng chụp để tối ưu hóa độ dẫn ion. Để đẩy nhanh quá trình tìm kiếm chúng, các nhà nghiên cứu đã tạo ra một robot có tên Clio nhận các thành phần được sử dụng để tạo ra chất điện phân và sau đó làm theo một số hướng dẫn để tạo ra một số mẫu.
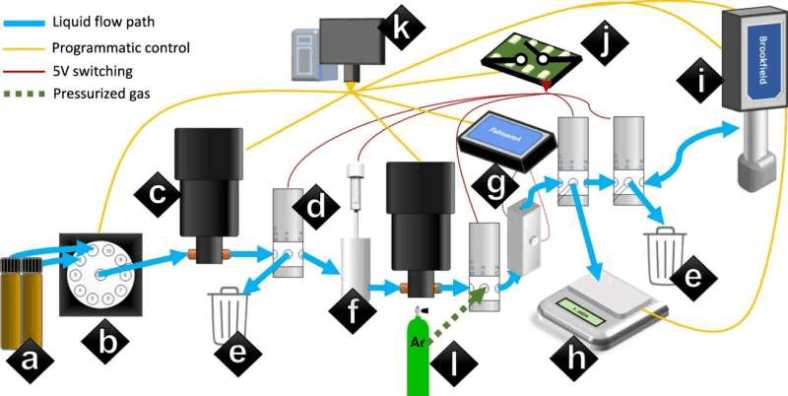
Sơ đồ của thí nghiệm chế tạo chất điện phân tự động của robot “Clio.” Sử dụng một loạt hai máy bơm lập trình để định lượng và chuyển một mẫu chất lỏng. Ảnh: Nature Communications. Năm 2022.
Sau đó, họ bổ sung một máy tính chạy ứng dụng AI học sâu (gọi là Dragonfly) chấp nhận dữ liệu từ Clio và từ các cảm biến trong chất điện phân do robot sản xuất. Dragonfly đã phân tích mẫu sau đó đề xuất những cải tiến có thể có. Clio đã chấp nhận những cải tiến và sử dụng chúng để tạo ra một mẫu mới. Hệ thống qua lại này được lặp lại nhiều lần (mỗi lần mất khoảng hai ngày) với chất điện giải dần dần được cải thiện. Tại một điểm do các nhà nghiên cứu chỉ định, cặp máy móc ngừng hoạt động, cho phép các nhà nghiên cứu kiểm tra các sản phẩm đã được sản xuất.
Trong thử nghiệm của họ, các nhà nghiên cứu nhận thấy rằng hệ thống ghép nối của họ hoạt động như hy vọng, họ thấy các mẫu chất điện phân được cải thiện dần dần loại tốt nhất được tìm thấy là tốt hơn 13% so với các loại pin hiệu suất cao nhất hiện nay trên thị trường.
Trong tương lai, các nhà nghiên cứu có kế hoạch tiếp tục tinh chỉnh hệ thống của họ để cho phép thử nghiệm nhiều mục tiêu hơn và có lẽ để làm cho nó chạy nhanh hơn.
Google đã thua Meta trong cuộc chiến về 'học máy'
Giờ đây, Google đang đặt cược tương lai các sản phẩm của chính mình vào một dự án AI nội bộ mới.
Vào năm 2015, Google về cơ bản đã tạo ra hệ sinh thái cho học máy hiện đại khi mở một dự án nghiên cứu nhỏ từ nhóm phát triển trí tuệ nhân tạo Google Brain, có tên là TensorFlow. Nó sau đó nhanh chóng trở nên phổ biến và biến công ty trở thành "ông trùm" quản lý các sản phẩm AI chính thống.
Nhưng ngày nay, câu chuyện đã khác, khi Google đã đánh mất vị thế của mình - bao gồm cả trái tim và khối óc của các nhà phát triển - vào tay Meta.
Từng là một công cụ học máy có mặt ở khắp nơi, TensorFlow của Google đã dần tụt hậu so với công cụ học máy PyTorch của Meta. PyTorch được phát triển lần đầu tiên tại Facebook và có nguồn mở ở dạng beta vào năm 2017. Và ngày nay, nó đang ngày càng được coi là người dẫn đầu trong lính vực này.
Video đang HOT

Trong khi Google vấp phải một loạt các sai lầm chiến thuật, Meta lại đưa ra được các quyết định phát triển hợp lý và vượt trội trong cộng đồng mã nguồn mở, tới mức các chuyên gia cho rằng cơ hội của Google để định hướng cho tương lai của lĩnh vực học máy trên Internet có thể sẽ không còn nữa. PyTorch đã trở thành công cụ phát triển máy học dành cho các nhà phát triển bình thường cũng như các nhà nghiên cứu khoa học.
"Học máy" là một lĩnh vực của trí tuệ nhân tạo liên quan đến việc nghiên cứu và xây dựng các kĩ thuật cho phép các hệ thống "học" tự động từ dữ liệu để giải quyết những vấn đề cụ thể.
Giờ đây, dưới cái bóng của PyTorch, Google đã âm thầm xây dựng một framework học máy mới, được gọi là JAX. Ban đầu, đây là từ viết tắt của "Just After eXecution", nhưng sau đó nó đã không còn là viết tắt của bất cứ điều gì. Nhiều người coi nó là thứ kế thừa TensorFlow.
Google Brain và công ty con DeepMind AI của Google đã từ chối triển khai mở rộng TensorFlow để dọn đường cho JAX, theo chia sẻ từ những người thân cận với dự án. Một đại diện của Google đã xác nhận rằng JAX hiện đã được áp dụng phổ biến tại Google Brain và DeepMind.
Ban đầu, JAX phải đối mặt với sự phản kháng đáng kể từ bên trong, theo chia sẻ từ những người trong cuộc. Những người này cho biết các nhân viên của Google đã quen với việc sử dụng TensorFlow. Tuy cách tiếp cận của JAX đơn giản hơn nhiều, nhưng dù sao điều này cũng đã thay đổi cách Google xây dựng phần mềm nội bộ, họ nói.
Những người có kiến thức về dự án cho biết công cụ này hiện được kỳ vọng sẽ trở thành nền tảng của tất cả các sản phẩm của Google sử dụng máy học trong những năm tới, giống như cách mà TensorFlow đã làm vào cuối những năm 2010.
Và JAX dường như đã thoát ra khỏi phạm vi hoạt động của Google, khi công ty phần mềm đám mây Salesforce nói rằng họ đã áp dụng nó trong các nhóm nghiên cứu của mình.
Viral Shah, người tạo ra ngôn ngữ lập trình Julia mà các chuyên gia thường so sánh với JAX cho biết:
"JAX là một kỳ công của kỹ thuật", Viral Shah, người tạo ra ngôn ngữ lập trình Julia, chia sẻ. "Tôi nghĩ về JAX như một ngôn ngữ lập trình riêng biệt sẽ được khởi tạo thông qua Python. Nếu bạn tuân thủ các quy tắc mà JAX muốn bạn làm, thì nó có thể làm được những điều kỳ diệu. Và thật đáng kinh ngạc về những gì nó có thể làm được."
Google hiện đang hy vọng đạt được thành công một lần nữa, đồng thời học hỏi từ những sai lầm đã mắc phải trong quá trình phát triển TensorFlow. Tuy nhiên, các chuyên gia cho rằng đó sẽ là một thách thức to lớn vì sự hiện diện của Meta và PyTorch.
Buổi hoàng hôn của TensorFlow và sự trỗi dậy của PyTorch
Theo các dữ liệu chính thống, sức ảnh hưởng của PyTorch đang cho thấy nó sắp bắt kịp TensorFlow. Dữ liệu về mức độ tương tác từ Stack Overflow cho thấy mức độ phổ biến của TensorFlow được đo bằng tỷ lệ các câu hỏi được hỏi trên diễn đàn của các nhà phát triển và chúng đã đình trệ trong những năm gần đây, trong khi mức độ tương tác của PyTorch tiếp tục tăng.
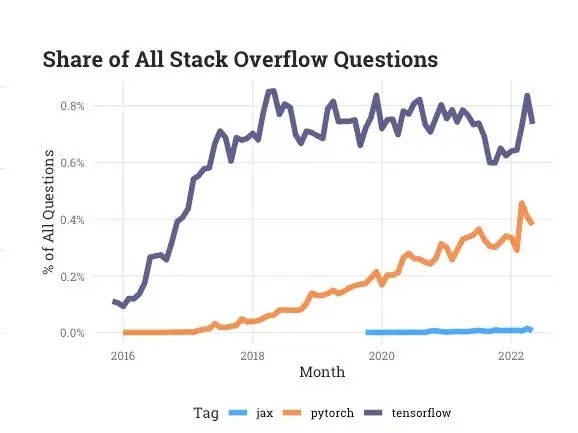
Khi không còn ai hỏi han, tức là sự quan tâm đã hết.
Ban đầu, TensorFlow phát triển mạnh mẽ và gần như bùng nổ sau khi ra mắt. Nhiều công ty lớn như Uber và Airbnb, thậm chí các tổ chức như NASA đã nhanh chóng chọn và bắt đầu sử dụng nó cho một số dự án phức tạp nhất của họ. Đó là các dự án đòi hỏi thuật toán đào tạo trên các tập dữ liệu lớn. Nó đã được tải xuống 160 triệu lần vào tháng 11/2020.
Nhưng các tính năng khủng khiếp và việc cập nhật liên tục của Google ngày càng khiến TensorFlow khó sử dụng và không thân thiện với người dùng, ngay cả những người trong nội bộ của Google, theo chia sẻ từ các nhà phát triển. Google đã phải thường xuyên cập nhật hệ thống của mình bằng các công cụ mới khi lĩnh vực học máy phát triển với tốc độ chóng mặt. Và khi ngày càng có nhiều người tham gia, dự án càng bị mở rộng, dẫn đến việc thiếu tập trung vào các thành phần cốt lõi ban đầu.
PyTorch là một framework học máy mã nguồn mở dựa trên thư viện Torch, được sử dụng cho các ứng dụng như thị giác máy tính và xử lý ngôn ngữ tự nhiên, chủ yếu được phát triển bởi Meta AI.
PyTorch, trong khi đó, đã ra mắt phiên bản đầy đủ vào năm 2018 từ phòng nghiên cứu trí tuệ nhân tạo của Facebook. Trong khi cả TensorFlow và PyTorch đều được xây dựng dựa trên Python, ngôn ngữ ưa thích của các chuyên gia học máy, thì Meta (hay Facebook trước đây) đã đầu tư rất nhiều vào việc phục vụ cộng đồng nguồn mở. PyTorch cũng được hưởng lợi từ mức độ tập trung vào việc làm tốt một số việc nhỏ, điều mà TensorFlow đã vô tình đánh mất.
"Chúng tôi chủ yếu sử dụng PyTorch; nó được cộng đồng ủng hộ nhiều nhất", Patrick von Platen, kỹ sư nghiên cứu tại công ty khởi nghiệp máy học Hugging Face, cho biết. "Chúng tôi nghĩ rằng PyTorch có lẽ đang làm tốt nhất với mã nguồn mở. Họ đảm bảo rằng các câu hỏi được trả lời trực tuyến. Các ví dụ đều hoạt động. PyTorch luôn có cách tiếp cận đầu tiên".
Một số tổ chức lớn cũng đang triển khai các dự án chạy trên PyTorch. Tesla và Uber cũng thực hiện các dự án nghiên cứu máy học khó nhất của họ trên PyTorch.
JAX, tương lai của học máy tại Google

Jeff Dean, Phó chủ tịch cấp cao của Google AI
Khi trận chiến giữa PyTorch và TensorFlow vẫn đang diễn ra, một nhóm nghiên cứu nhỏ bên trong Google đã làm việc trên một framework (các đoạn code đã được viết sẵn, cấu thành nên một bộ khung và các thư viện lập trình được đóng gói) mới giúp truy cập dễ dàng hơn vào các chip được xây dựng tùy chỉnh - được gọi là đơn vị xử lý tensor hoặc TPU - làm nền tảng cho phương pháp tiếp cận trí tuệ nhân tạo và chỉ có thể truy cập thông qua TensorFlow.
Các nhà nghiên cứu của nhóm bao gồm Roy Frostig, Matthew James Johnson và Chris Leary. Cả 4 người đã phát hành một bài báo vào năm 2018 với tiêu đề "Biên dịch các chương trình học máy thông qua truy tìm cấp cao", mô tả những gì sau này đã trở thành JAX.
Adam Paszke, một trong những tác giả ban đầu của PyTorch khi còn làm việc tại Facebook, cũng bắt đầu làm việc với Johnson vào năm 2019 khi còn là sinh viên và đã tham gia nhóm JAX vào đầu năm 2020.
Dự án mới, JAX, đã đưa ra một cách thiết kế đơn giản hơn để xử lý một trong những vấn đề phức tạp nhất trong lĩnh vực học máy: dàn trải công việc của một vấn đề lớn trên nhiều chip. Thay vì chạy các đoạn mã riêng lẻ cho các chip riêng biệt, JAX tự động phân phối công việc. Nó cho phép truy cập ngay lập tức vào nhiều TPU mà bạn cần để làm bất cứ điều gì bạn muốn.
JAX đã giải quyết một vấn đề cơ bản mà các nhà nghiên cứu của Google phải đối mặt khi nghiên cứu các vấn đề ngày càng lớn và ngày càng cần nhiều sức mạnh tính toán hơn.
Thách thức lớn nhất của Google là chiến lược của Meta với PyTorch

Cả PyTorch và TensorFlow đều bắt đầu theo cùng một cách. Đầu tiên, chúng là các dự án nghiên cứu, sau đó dần trở thành tiêu chuẩn trong nghiên cứu máy học. Sau đó, các nhà nghiên cứu đã đưa chúng tới phần còn lại của thế giới.
Tuy nhiên, JAX phải đối mặt với một số thách thức. Đầu tiên là nó vẫn dựa trên các framework khác theo nhiều cách. Các nhà phát triển và chuyên gia nói rằng JAX không đưa ra cách tải dữ liệu và xử lý trước dữ liệu một cách dễ dàng, đòi hỏi TensorFlow hoặc PyTorch phải xử lý phần lớn quá trình thiết lập.
Khung cơ bản của JAX, XLA , cũng chỉ đang được tối ưu hóa cao cho các TPU của Google. Nó tất nhiên cũng hoạt động với nhiều GPU và CPU truyền thống, nhưng vẫn chưa thể đạt được mức ngang bằng với TPU.
Người phát ngôn của Google cho biết việc tập trung vào TPU là do... sự nhầm lẫn về tổ chức và chiến lược từ năm 2018 đến năm 2021, dẫn đến việc không đầu tư và có mức độ ưu tiên dưới mức tối ưu cho hỗ trợ GPU, cũng như thiếu sự hợp tác với nhà cung cấp GPU lớn. Các vấn đề này đang nhanh chóng được cải thiện. Người phát ngôn cho biết nghiên cứu nội bộ của Google cũng chủ yếu tập trung vào TPU, dẫn đến việc thiếu các vòng phản hồi tốt cho việc sử dụng GPU.
"Bất cứ điều gì được thực hiện để tạo lợi thế cho phần cứng này so với phần cứng khác sẽ ngay lập tức bị coi là hành vi xấu, và nó sẽ bị từ chối trong cộng đồng mã nguồn mở", Andrew Feldman, CEO của Cerebras Systems, một công ty khởi nghiệp trị giá 4 tỷ USD, cho biết. " Không ai muốn bị khóa vào một nhà cung cấp phần cứng duy nhất, đó là lý do tại sao các framework học máy xuất hiện. Những người thực hành công nghệ máy học muốn đảm bảo rằng các mô hình của họ là di động, để họ có thể đưa chúng đến bất kỳ nền tảng phần cứng nào họ chọn và không bị khóa với chỉ một nền tảng."
Đồng thời, bản thân PyTorch hiện đã gần 6 năm tuổi, vượt qua độ tuổi mà TensorFlow lần đầu tiên bắt đầu có dấu hiệu chậm lại. Không rõ liệu dự án của Meta có gặp số phận tương tự như phiên bản tiền nhiệm được Google hậu thuẫn hay không, nhưng điều đó có nghĩa đây là thời điểm thích hợp cho một cái gì đó mới xuất hiện. Và một số chuyên gia đã chỉ ra rằng với quy mô của Google, thì các nhà phê bình đừng bao giờ coi thường "gã khổng lồ trong lĩnh vực tìm kiếm".
Nhân lực trí tuệ nhân tạo Việt 'như muối bỏ bể'  Trong khi nhu cầu phát triển lĩnh vực trí tuệ nhân tạo rất nhiều, số lượng nhân lực có chuyên môn lại thiếu phần lớn và việc đào tạo chỉ đáp ứng được nhu cầu rất nhỏ. Trí tuệ nhân tạo (AI) và nguồn nhân lực Việt đáp ứng cho nhu cầu phát triển lĩnh vực này trên cả nước đang là vấn...
Trong khi nhu cầu phát triển lĩnh vực trí tuệ nhân tạo rất nhiều, số lượng nhân lực có chuyên môn lại thiếu phần lớn và việc đào tạo chỉ đáp ứng được nhu cầu rất nhỏ. Trí tuệ nhân tạo (AI) và nguồn nhân lực Việt đáp ứng cho nhu cầu phát triển lĩnh vực này trên cả nước đang là vấn...
Tin liên quan
 Ứng dụng trí tuệ nhân tạo trong đời sống
Ứng dụng trí tuệ nhân tạo trong đời sống AI tạo ra bước nhảy vọt về năng suất cho các doanh nghiệp
AI tạo ra bước nhảy vọt về năng suất cho các doanh nghiệp Tranh cãi về việc AI có thể xóa sổ nhân loại
Tranh cãi về việc AI có thể xóa sổ nhân loại Các nhà khoa học Nhật Bản nhắm tới phát triển trí tuệ nhân tạo biết cười
Các nhà khoa học Nhật Bản nhắm tới phát triển trí tuệ nhân tạo biết cười Mỹ quyết bóp nghẹt ngành chip trí tuệ nhân tạo của Trung Quốc
Mỹ quyết bóp nghẹt ngành chip trí tuệ nhân tạo của Trung Quốc Công nghệ AI giúp trò chuyện với người đã mất
Công nghệ AI giúp trò chuyện với người đã mất
 Clip: Nam thanh niên bỗng dưng lao đầu xuống đường đúng lúc ô tô tới, cảnh tượng sau đó gây kinh hãi00:53
Clip: Nam thanh niên bỗng dưng lao đầu xuống đường đúng lúc ô tô tới, cảnh tượng sau đó gây kinh hãi00:53 Hy hữu nam thanh niên nghi say thuốc lào ngã ra đường bị ô tô tông trúng00:53
Hy hữu nam thanh niên nghi say thuốc lào ngã ra đường bị ô tô tông trúng00:53 Ông chú 40 trêu ghẹo cô gái 17 tuổi, bị phản ứng liền đập vỡ kính quán ăn00:57
Ông chú 40 trêu ghẹo cô gái 17 tuổi, bị phản ứng liền đập vỡ kính quán ăn00:57 Đoạn video 38 giây từ camera an ninh siêu thị trở thành nỗi ám ảnh cả đời của một người mẹ: Không ai đoán được những gì diễn ra sau đó00:39
Đoạn video 38 giây từ camera an ninh siêu thị trở thành nỗi ám ảnh cả đời của một người mẹ: Không ai đoán được những gì diễn ra sau đó00:39 Cảnh sát đột kích "sào huyệt" tổ chức quốc tế lừa đảo hàng trăm tỷ đồng02:24
Cảnh sát đột kích "sào huyệt" tổ chức quốc tế lừa đảo hàng trăm tỷ đồng02:24 1 Anh Trai cảm thấy "không được tôn trọng", có phát ngôn chia rẽ nhà Hoa Dâm Bụt00:50
1 Anh Trai cảm thấy "không được tôn trọng", có phát ngôn chia rẽ nhà Hoa Dâm Bụt00:50 Xe Camry quay đầu giữa giao lộ thì "chạm trán" Lexus giá gần chục tỷ đồng00:36
Xe Camry quay đầu giữa giao lộ thì "chạm trán" Lexus giá gần chục tỷ đồng00:36 Lan truyền video SOOBIN ôm ấp fan khi diễn trong quán bar, bùng nổ tranh cãi kịch liệt00:18
Lan truyền video SOOBIN ôm ấp fan khi diễn trong quán bar, bùng nổ tranh cãi kịch liệt00:18 Lời khai của chủ tịch hội nông dân xã đột nhập cướp tại nhà lãnh đạo HĐND tỉnh11:25
Lời khai của chủ tịch hội nông dân xã đột nhập cướp tại nhà lãnh đạo HĐND tỉnh11:25 Bà xã Vũ Cát Tường gây xao xuyến với visual đẹp nức lòng, cùng chú rể trao điệu nhảy tình tứ trong MV đám cưới04:21
Bà xã Vũ Cát Tường gây xao xuyến với visual đẹp nức lòng, cùng chú rể trao điệu nhảy tình tứ trong MV đám cưới04:21 Truy bắt kẻ táo tợn dùng búa đập phá tủ, cướp tiệm vàng ở Lâm Đồng00:19
Truy bắt kẻ táo tợn dùng búa đập phá tủ, cướp tiệm vàng ở Lâm Đồng00:19Tin đang nóng
 Vụ Kim Sae Ron qua đời ở nhà riêng: Được phát hiện trong tình trạng bất tỉnh ngừng tim, không còn khả năng cứu chữa khi vào bệnh viện
Vụ Kim Sae Ron qua đời ở nhà riêng: Được phát hiện trong tình trạng bất tỉnh ngừng tim, không còn khả năng cứu chữa khi vào bệnh viện Vì sao dân mạng sốc khi Kim Sae Ron qua đời ngay đúng ngày sinh nhật của Kim Soo Hyun?
Vì sao dân mạng sốc khi Kim Sae Ron qua đời ngay đúng ngày sinh nhật của Kim Soo Hyun? Con gái nuôi Phi Nhung kết hôn
Con gái nuôi Phi Nhung kết hôn Kim Sae Ron sống cô độc, liên tục vào viện điều trị 1 vấn đề ngay trước khi qua đời
Kim Sae Ron sống cô độc, liên tục vào viện điều trị 1 vấn đề ngay trước khi qua đời Sao nam Vbiz và vợ kém 17 tuổi có con thứ 2?
Sao nam Vbiz và vợ kém 17 tuổi có con thứ 2? Mâu thuẫn tiền bạc, anh rể cưa phá hàng trăm gốc cây trong vườn nhà em dâu
Mâu thuẫn tiền bạc, anh rể cưa phá hàng trăm gốc cây trong vườn nhà em dâu Bộ phim đỉnh nhất của Kim Sae Ron: Diễn xuất xứng đáng phong thần, làm nên điều không tưởng ở Cannes
Bộ phim đỉnh nhất của Kim Sae Ron: Diễn xuất xứng đáng phong thần, làm nên điều không tưởng ở Cannes Ca sĩ Hoài Lâm livestream bán hàng, nghệ sĩ Trường Giang lạ lẫm
Ca sĩ Hoài Lâm livestream bán hàng, nghệ sĩ Trường Giang lạ lẫmTin mới nhất
Nâng cao và biến đổi hình ảnh của bạn bằng trình chỉnh sửa video trực tuyến CapCut

Cách đăng Facebook để có nhiều lượt thích và chia sẻ

Thêm nhiều bang của Mỹ cấm TikTok

Microsoft cấm khai thác tiền điện tử trên các dịch vụ đám mây để bảo vệ khách hàng

Facebook trấn áp hàng loạt công ty phần mềm gián điệp

Meta đối mặt cáo buộc vi phạm các quy tắc chống độc quyền với mức phạt 11,8 tỷ đô

Không cần thăm dò, Musk nên sớm từ chức CEO Twitter

Đại lý Việt nhập iPhone 14 kiểu 'bia kèm lạc'

Khai trương hệ thống vé điện tử và dịch vụ trải nghiệm thực tế ảo XR tại Quần thể Di tích Cố đô Huế
'Dở khóc dở cười' với tính năng trợ giúp người bị tai nạn ôtô của Apple

Xiaomi sa thải hàng nghìn nhân sự

Apple sẽ bắt đầu sản xuất MacBook tại Việt Nam vào giữa năm 2023
Có thể bạn quan tâm

Omega-3 có nhiều nhất trong thực phẩm nào?
Sức khỏe
06:19:52 17/02/2025
Cuộc chiến tài sản của Từ Hy Viên: Còn 2 nhân vật bí ẩn, quyền lực đang ở đâu?
Sao châu á
06:16:59 17/02/2025
Sao nữ Vbiz từng vướng tin hẹn hò đồng giới nay công khai video tình tứ bên người mới
Sao việt
06:10:10 17/02/2025
Vào mùa xuân nên ăn nhiều 3 loại rau mầm này, vừa mát gan giải nhiệt lại tăng sức đề kháng khi thời tiết thay đổi
Ẩm thực
06:07:14 17/02/2025
'Trung tâm chăm sóc chấn thương' ăn khách, bộ ba diễn viên chính được săn đón
Hậu trường phim
06:02:56 17/02/2025
Học trò Đàm Vĩnh Hưng gây tiếc nuối ở 'Giọng hát Việt' ra sao sau 10 năm?
Nhạc việt
06:00:40 17/02/2025
Phim Việt gây chấn động vì cảnh 2 đại mỹ nhân vạch mặt nhau căng thẳng như Diên Hi Công Lược
Phim việt
05:59:39 17/02/2025
Phim Hoa ngữ cực hay nhưng bị nhà đài chê thẳng mặt: Cặp chính đẹp như tiên đồng ngọc nữ cũng "hết cứu"?
Phim châu á
05:59:04 17/02/2025
(Review): 'The Gorge': Phim tình cảm 'sến' và dữ dội của Anya Taylor-Joy
Phim âu mỹ
05:58:23 17/02/2025
CSGT xuyên đêm tuần tra, phát cảnh báo trên các tuyến đường mưa trơn trượt
Tin nổi bật
23:44:42 16/02/2025
 Lễ tiễn biệt Từ Hy Viên: Gia đình ca hát vui vẻ, chồng Hàn gầy rộc sút hơn 7 kg sau biến cố
Lễ tiễn biệt Từ Hy Viên: Gia đình ca hát vui vẻ, chồng Hàn gầy rộc sút hơn 7 kg sau biến cố Cú "ngã ngựa" cay đắng của mỹ nữ 1m5 đình đám nhất Vbiz
Cú "ngã ngựa" cay đắng của mỹ nữ 1m5 đình đám nhất Vbiz Người mẫu Xuân Mai đột ngột qua đời ở tuổi 29
Người mẫu Xuân Mai đột ngột qua đời ở tuổi 29 Tình cũ Thiều Bảo Trâm muốn yên lặng nhưng sao Hoa hậu Lê Hoàng Phương vẫn không ngừng úp mở?
Tình cũ Thiều Bảo Trâm muốn yên lặng nhưng sao Hoa hậu Lê Hoàng Phương vẫn không ngừng úp mở? Sự thật về thông tin trâu chọi ở Vĩnh Phúc bị chích điện đến chết giữa sân đấu
Sự thật về thông tin trâu chọi ở Vĩnh Phúc bị chích điện đến chết giữa sân đấu Sao nữ Vbiz nhiễm cúm B với 1 triệu chứng nặng, sững người khi bác sĩ nói tình trạng bệnh
Sao nữ Vbiz nhiễm cúm B với 1 triệu chứng nặng, sững người khi bác sĩ nói tình trạng bệnh Tậu xe sang 7 tỷ ở tuổi 19, Lọ Lem kiếm tiền từ đâu?
Tậu xe sang 7 tỷ ở tuổi 19, Lọ Lem kiếm tiền từ đâu? Nữ sinh "điên cuồng" ra rạp xem Na Tra 31 lần trong 8 ngày bị chê phung phí, người cha tiết lộ nguyên nhân đau lòng phía sau
Nữ sinh "điên cuồng" ra rạp xem Na Tra 31 lần trong 8 ngày bị chê phung phí, người cha tiết lộ nguyên nhân đau lòng phía sau Cô giáo mang thai bất ngờ bị nhóm phụ huynh tố cáo lên hiệu trưởng, lý do được tiết lộ khiến netizen bức xúc: Không thể hiểu nổi!
Cô giáo mang thai bất ngờ bị nhóm phụ huynh tố cáo lên hiệu trưởng, lý do được tiết lộ khiến netizen bức xúc: Không thể hiểu nổi!