Tìm hiểu cách thức các đại gia công nghệ quản lý dữ liệu
 Chủ tịch Sony sắp nghỉ hưu
Chủ tịch Sony sắp nghỉ hưu Motorola X sở hữu cấu hình phần cứng cực “khủng”
Motorola X sở hữu cấu hình phần cứng cực “khủng”Trong thế giới hiện đại ngày nay, đằng sau mỗi thao tác đơn giản của chúng ta trên thế giới mạng là cả một hệ thống đồ sộ đang vận hành. Từng giờ, từng giây trên thế giới có hàng chục triệu người đang sử dụng dịch vụ của các hãng công nghệ lớn trên thế giới như Google, Yahoo, Microsoft, Facebook..v.v.. Điều này đòi hỏi sức mạnh từ của hàng ngàn bộ xử lý trên hàng ngàn server của các hãng này. Chỉ tính riêng công việc trả về kết quả tìm kiếm mỗi khi người dùng gõ từ khóa vào search box, Google dã phải vận hành hàng loạt server đặt khắp thế giới, liên tục thực hiện thuật toán tìm kiếm cũng như sục sạo khắp thế giới web để có được một bức tranh toàn cảnh sẵn sàng được sử dụng để phục vụ người dùng một cách nhanh nhất. Với cường độ hoạt động 24/7, 365 ngày/ năm không có lấy một giây ngơi nghỉ, riêng việc phục vụ nhu cầu tìm kiếm đã đòi hỏi các hệ thống của Google xử lý xấp xỉ 20 petabyte dữ liệu mỗi ngày, một con số mà người bình thường khó có thể tưởng tượng ra nổi.
Ở tầm vóc này, mọi sai lầm dù là nhỏ nhất, dù là trong khâu thiết kế hay triển khai cũng có tiềm năng gây hậu quả lâu dài. Mọi công việc từ bổ sung dung lượng lưu trữ đến thay đổi đôi chút kết cấu cơ sở dữ liệu đều sẽ cần được được cân nhắc kỹ lưỡng, và quan trọng nhất là cần một thiết kế hợp lý để không làm ảnh hưởng đến hàng triệu người dùng đang “kêu gào” đòi hỏi ngoài kia. Với hàng trăm ngàn người dùng đang online và hàng ngàn terabyte dữ liệu được đọc/ghi ngay cả vào những thời điểm hệ thống đang được nâng cấp, các giải pháp công nghệ đơn giản của các trung tâm dữ liệu thông thường sẽ khó mà phù hợp cho quy mô này. Vậy rốt cuộc, những người khổng lồ công nghệ này quản lý dữ liệu của mình như thế nào để đáp ứng nhu cầu ngày càng gia tăng đó? Qua bài viết của Arcstechnica, chúng ta hãy cùng điểm qua một vài giải pháp dễ hiểu nhất mà Google, Amazon và Microsoft sử dụng.

Google File System
Không lấy gì làm lạ khi Google là một trong những hãng đầu tiên phải đối mặt với bài toán về lưu trữ khi xét đến số lượng người dùng mà hãng này phục vụ. Lời giải được các kỹ sư của hãng đưa ra vào năm 2003 là hệ thống lưu trữ phân tán, được tối ưu cho các dịch vụ mà Google cung cấp: Google File System (GFS). Có thể nói GFS là xương sống cho hầu hết mọi dịch vụ mà Google cung cấp. Hệ thống cơ sở dữ liệu người dùng đồ sộ, các dịch vụ điện toán đám mây và lượng dữ liệu khổng lồ phục vụ việc tìm kiếm, tất cả đều được quản lý dựa trên GFS.
Các chi tiết kỹ thuật GFS dĩ nhiên là được Google…giữ kín cho riêng mình, nhưng chúng ta vẫn có thể hình dung ra phần nào cách hệ thống này vận hành dựa trên những gì mà kỹ sư trưởng Howard Gobioff và Shun-Tak Leung chia sẻ hồi năm 2003. Tiêu chí hoạt động của GFS có thể gói gọn trong một câu: binh quý hồ…đa. Nói cách khác, với quy mô dữ liệu mà mình phải vận hành, các kỹ sư thiết kế GFS coi trọng khả năng mở rộng hệ thống, tăng số lượng server và ổ cứng thay vì đầu tư quá nhiều vào việc tạo ra các server hay thiết bị lưu trữ chất lượng cao. Google muốn kết hợp các server cũng như thiết bị lưu trữ rẻ và đơn giản thành một hệ thống với khả năng chịu lỗi cao nhất có thể. Như thế nào ư? Hãy nhìn vào câu phát biểu sau đây.

Nói cụ thể ra một chút, với cường độ hoạt động mà người dùng và Google đòi hỏi, các Server này sớm muộn cũng sẽ…ra đi. Và thiết kế của GFS được tạo ra để bảo đảm rằng, dù có phải thường xuyên thay đổi các server trong hệ thống, lượng dữ liệu bị mất đi vẫn sẽ được giữ ở mức tối thiểu. Trong các hệ thống của mình, Google thường lưu trữ dữ liệu trên các file dung lượng cực lớn, và các file này sẽ được đọc, ghi, sử dụng bởi rất nhiều ứng dụng tại cùng một thời điểm. Vì vậy GFS còn cần một đặc tính nữa là khả năng cung cấp lượng lớn dữ liệu ở tốc độ cao cho các ứng dụng này trong mọi thời điểm.
Video đang HOT
Để đáp ứng được 2 yêu cầu kể trên (tốc độ và khả năng chịu lỗi), hiển nhiên ta sẽ nghĩ ngay đến công nghệ RAID, và quả thực GFS hoạt động với cơ chế tương tự. Các tập hợp, gói file dữ liệu với dung lượng được định sẵn sẽ được rải đều trên một số cụm (cluster) server. Với cách tiếp cận như đã nêu: sử dụng các phần cứng giá thành rẻ, lấy số lượng lớn để bù đắp cho hiệu năng; sẽ là không ngoa khi nói các server này của Google “thăng” với tần suất khá thường xuyên, nhưng số lượng dữ liệu bị mất vẫn luôn được giữ ở mức hết sức tối thiểu.

Tuy nói là “tương tự”, nhưng quả thực trừ việc tăng tốc độ truy xuất và khả năng chịu lỗi, GFS khác rất nhiều so với RAID. Các server kể trên có thể nằm trong các dải mạng khác nhau, có lúc thuộc cùng datacenter, có lúc thậm chí còn không thuộc cùng một datacenter (tùy thuộc vào việc các file dữ liệu trên đó phục vụ việc gì). Quy mô của hai công nghệ rất chênh lệch. Với quy môt hoạt động của Google, khi nhắc đến “lưu trữ” thì ổ đĩa cứng là cách nghĩ quá hạn hẹp.
Điều này còn được thể hiện trong cách nhìn nhận đơn vị dữ liệu. Trong GFS, các kỹ sư chú trọng đến việc cung cấp dữ liệu theo từng khối cho việc xử lý, vì vậy khả năng cho phép đọc lượng lớn dữ liệu ở tốc độ cao là quan trọng nhất, còn tốc độ đọc hay ghi từng file vẫn chỉ được xếp vào hàng thứ yếu. Như các kỹ sư đã nêu trong bài viết của mình “Việc thực hiện một thay đổi bất kỳ trên từng file dĩ nhiên vẫn được hỗ trợ trong GFS, nhưng không được ưu tiên và hiệu năng của việc này cũng không được chú trọng tối ưu”. Nói dễ hiểu hơn, với quy mô của mình – GFS chủ yếu làm việc với dữ liệu theo từng khối, có thể bao gồm hàng triệu file với dung lượng từ hàng trăm MB đến vài GB. Và bởi các file dữ liệu này sẽ được rất nhiều ứng dụng sử dụng tại cùng một thời điểm, một cơ chế chịu lỗi khác cũng được thiết kế để bảo đảm rẵng mối khi có một thao tác ghi (write) xảy ra lỗi, dữ liệu sẽ có thể được rollback lại thời điểm ngay trước đó mà không làm ảnh hưởng đến các ứng dụng khác. Làm được điều này một cách chính xác mà không gây ảnh hưởng lớn đến hiệu năng là cả một kỳ công.
GFS gồm ba lớp: các GFS client sẽ xử lý các yêu cầu truy xuất dữ liệu của các ứng dụng; GFS master chuyên quản lý việc phân phối và theo dõi vị trí của các khối dữ liệu trên các cụm server (mỗi cụm chứa cùng loại dữ liệu), cũng như các file nằm trong đó (có thể nói dễ hiểu là các tiếp tân và một tay…thủ kho); cuối cùng chính là các server. Ngày trước, khi mà mọi thứ còn “đơn giản”, mô hình cơ bản sẽ là một master cho mỗi cụm server, các Client được đặt rải rác khắp nơi có thể liên lạc với bất kỳ Master nào khi cần. Nhưng hiện nay với nhu cầu ngày càng gia tăng của thế giới web, Google đã phải mở rộng mô hình phát triển một hệ thống master mới chuyên để quản lý các master cấp dưới, thông tin cụ thể về hệ thống này đáng tiếc lại chưa được hé lộ đầy đủ
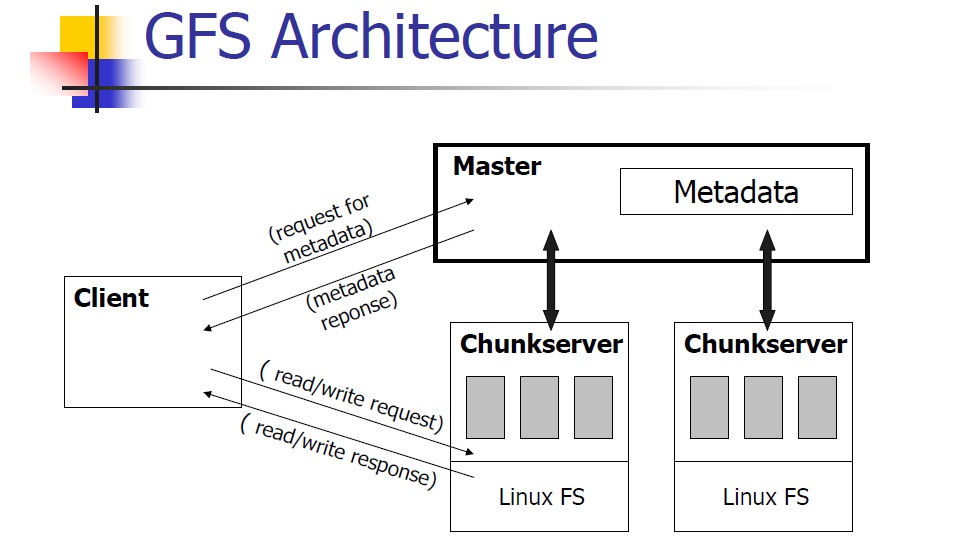
Khi GFS client nhận được yêu cầu về một file dữ liệu từ một ứng dụng nào đó, nó sẽ gửi yêu cầu về thông tin vị trí của file này cho server master. Server master sẽ cung cấp vị trí của một trong các server/cụm server có chứa file đó (nhớ rằng các máy này đóng vai trò như các RAID trong hệ thống nhỏ mà ta thường gặp). Nếu việc kết nối thành công, GFS Client sẽ làm việc trực tiếp với server dữ liệu đó để lấy file, Master sẽ không tham gia vào quá trình giao tiếp này trừ khi có lỗi xảy ra buộc Client phải quay lại “cầu cứu”.
Để đổi lại tốc độ cung cấp dữ liệu, các kỹ sư thiết kế GFS quyết định đánh đổi một phần tính nhất quán (consistency) của hệ thống. Hệ thống vẫn chịu lỗi tốt, vì như đã nói nếu có trục trặc trong quá trình ghi mọi thứ liên quan sẽ được rollback, đồng thời Client có thể sẽ được cung cấp một địa chỉ lưu trữ khác để tìm cách ghi dữ liệu đó lần nữa nếu trục trặc tiếp tục xảy ra. Nhưng do Master không trực tiếp theo dõi quá trình trao đổi giữa Client và các server dữ liệu, các thao tác “ghi” mà Client thực hiện trên một server sẽ không lập tức được đồng bộ với các bản sao của nó trong cùng cụm đó. Giải pháp của Google cho vấn đề này là “relaxed consistency model” (Tạm dịch: mô hình nhất quán lỏng). Nói một cách đơn giản thì lý thuyết này cho rằng nếu nhu cầu đang cấp thiết thì cung cấp cho Client địa chỉ của một server chứa dữ liệu hơi cũ cũng… chẳng sao, miễn sao sau đó các thay đổi trên khối dữ liệu sẽ được đồng bộ vào…một lúc nào đó. Theo từng chu kỳ, Master sẽ tìm kiếm thay đổi trên các khối dữ liệu của các server (được quản lý theo “phiên bản” – version) và bảo đảm việc đồng bộ được diễn ra thường xuyên nhất có thể mà vẫn không làm Client phải chờ lâu. Nếu có một server dữ liệu nào đó tụt lại quá xa – ví dụ như có quá nhiều khối dữ liệu cũ hoặc một khối nào đó quá cũ, Master sẽ bảo đảm nó không được “giới thiệu” cho Client nữa đến khi được cập nhật bằng bạn bằng bè.
Nhưng vẫn còn hai vấn đề, tại thời điểm Master phát hiện ra kẻ “tụt hậu” này, các phiên làm việc của Client với nó vẫn tiếp diễn. Client sẽ không biết được các dữ liệu trên đó là phiên bản cũ cho đến khi Master cập nhật cơ sở dữ liệu của mình. Bản thân cơ sở dữ liệu này của Master cũng được sao lưu ra nhiều nơi phòng khi Master hỏng, và không có Master thì các cụm server dữ liệu đó sẽ trở nên vô dụng. Tuy nhiên các thay đổi mà Client thực hiện trên dữ liệu tại thời điểm Master “thăng” cũng sẽ mất và gây ảnh hưởng đến tính nhất quán, bất kể có backup thường xuyên thế nào đi chăng nữa. Một lần nữa điều này được giải quyết bằng lý thuyết chứ không phải bằng một công nghệ đột phá gì: đại đa số các dữ liệu phục vụ việc tìm kiếm không cần phải được cập nhật mới với tốc độ quá khủng khiếp (đó cũng là lí do cho phát biểu ở trên: việc lấy lượng lớn dữ liệu ra mới là quan trọng”), và các thay đổi thường là bổ sung dữ liệu mới, chứ không phải thay thế dữ liệu cũ. Hai vấn đề cùng được giải quyết chỉ bằng một lý luận ngắn gọn này, nhưng rốt cuộc điều đó chỉ đúng với bộ máy tìm kiếm mà thôi.
Bigtable

Như bạn đọc cũng đoán được, khi Google bổ sung các dịch vụ khác như Youtube, Google Docs .v.v.. việc chỉ dựa vào một hệ thống quản lý dữ liệu theo từng khối, tại không chú trọng tính nhất quán là hoàn toàn không phù hợp. Để giải quyết vấn đề này, trên nền GFS hãng đã bổ sung Bigtable, công nghệ quản lý dữ liệu có dạng như một cơ sở dữ liệu. Mọi thứ được quản lý dưới dạng “bảng” (table) (cũng là lý do nhiều người coi BigTable có dạng như cơ sở dữ liệu dù rằng nói chính xác thì không phải vậy). Với hàng tỷ (vâng, hàng tỷ) webpage cần được lưu, các BigTable có tên hàng là các URL và các đặc tính liên quan của webpage đó (keyword, ngôn ngữ.v.v. ) làm tên các cột. Nội dung của trang đó sẽ được lưu vào các ô tương ứng với thông tin về thời điểm ghi, phiên bản (timestamp). Về cơ bản, cách mà Bigtable xử lý dữ liệu cũng vẫn khá giống GFS: ưu tiên việc đọc dữ liệu hơn và các thay đổi chủ yếu được thực hiện dưới dạng bổ sung, đi kèm là một chỉ số “phiên bản” chứ không trực tiếp thay đổi các dữ liệu cũ (kể cả là các dữ liệu cho dịch vụ dạng Google Docs cũng được quản lý theo dạng này). Tuy vậy cách tổ chức dạng bảng này cũng đủ khác biệt để giúp khắc phục các khó khăn trước đó mà Google gặp phải khi mở rộng số lượng dịch vụ mà chỉ dựa vào GFS. Như chúng ta đều thấy, các dịch vụ mail, video, calendar.v.v.. chúng ta đang sử dụng ngày nay được cập nhật mới khá chính xác. Đi sâu hơn về chi tiết kỹ thuật, Bigtable sẽ khá khó hiểu cho những ai không có nền tảng về cơ sở dữ liệu cũng như hệ thống thông tin nói chúng, vì vậy chúng ta sẽ từ biệt Google ở đây để chuẩn bị “nhòm ngó” Amazon và Microsoft trong các bài sắp tới.
Theo Genk
Các đại gia công nghệ đều muốn sở hữu một nền tảng
Những năm 1990, rất nhiều các công ty công nghệ được đầu tư và cũng rất nhiều đã trở thành công ty đại chúng. Thị trường chứng khoán đã đưa các công ty ấy lên đến đỉnh cao rồi lâm vào khủng hoảng. Chỉ một số công ty tồn tại được. Những công ty đã thất bại chính là những công ty dựa vào lượng khách truy cập trang web của họ, bởi đa phần những trang web lúc đó chỉ là những trang "quảng cáo" cho sản phẩm thực tế của họ.

Những công ty tồn tại được qua đợt khủng hoảng ấy khéo léo hơn, được đầu tư tốt hơn và bản chất của họ không chỉ dừng ở một trang "giới thiệu sản phẩm". Họ đã đưa công nghệ lên một trình độ mới, với việc sáng tạo ra những cách thức hoàn toàn mới để kinh doanh. Hãy nghĩ đến Amazon, eBay và Google. Họ không phải là đại diện kỹ thuật số cho việc kinh doanh offline của họ. Thực tế thì cả 3 công ty này đều không hề có mảng kinh doanh offline nào. Nhưng những gì họ làm đã thay đổi cách thức thương mại truyền thống hoạt động.
Thời đại hiện nay cũng có chút giống với những năm 1990, khi mà rất nhiều các công ty công nghệ có thể thu hút vốn đầu tư hay có chỗ trong các vườn ươm. Trong khi những năm 1990, các công ty đa phần là những trang web "giới thiệu sản phẩm" thì hiện nay đa phần là những công cụ tiện ích. Các startup tập trung chỉ vào 1 điểm thường dễ nhận được đầu tư hơn các startup khác. Lý do ư? Có lẽ đó là xu hướng muốn tìm một Instagram tiếp theo của các nhà đầu tư. Instagram là một công cụ chia sẻ và chỉnh sửa ảnh, cực kỳ phổ biến với giới trẻ, và mặc dù chưa hề có một mô hình kinh doanh đem lại doanh thu nhưng đã được Facebook mua lại với giá lên đến 1 tỷ USD. Và giờ đây tất cả mọi người đều cố gắng trở thành một Instagram thứ hai. Nhưng liệu mô hình chỉ tập trung giải quyết 1 nhu cầu này có bền vững không?
Câu trả lời của biên tập viên Darcy Travlos của Forbes là Không. Theo cô thì những công ty công nghệ có khả năng trở thành một nền tảng hoặc một sinh thái mới là những công ty bền vững, và có thể thu hút được những đầu tư dài dạn. Cô đã chỉ ra những ví dụ rất thực tế với Apple, LinkedIn, Amazon, eBay, Google và Facebook.
Apple là một ví dụ rất tuyệt vời. Họ đã tạo ra cả một quan niệm mới - công nghệ tiêu dùng - tại một thời điểm mà thế giới đều đang hướng về công nghệ doanh nghiệp (ví dụ như Cisco). Apple là hình mẫu lý tưởng cho việc thiết lập một nền tảng công nghệ tiêu dùng. Họ là người đầu tiên, và cũng là người cực kỳ thành công, tập trung vào một hệ thống công nghệ dành cho người tiêu dùng và làm ngạc nhiên cả các nhà đầu tư phố Wall. Sản phẩm tiêu dùng thành công đầu tiên của Apple là iPod, và Apple đã tận dụng điều này để tạo nên cả một hệ sinh thái xây dựng trên hệ điều hành và các sản phẩm khép kín của hãng. Kết quả? Sau 10 năm, giá cổ phiếu của Apple tăng từ 7,1 USD lên 705 USD, với doanh thu tăng hàng trăm phần trăm.
LinkedIn thì phát triển từ một mạng lưới dành cho các chuyên gia đến một nền tảng dành cho cả ngành công nghiệp tuyển dụng chuyên nghiệp. Thậm chí cả BranchOut, công ty nhận được rất nhiều quan tâm trong năm ngoái nhờ khả năng sử dụng thông tin bạn bè trên Facebook để tuyển dụng, cũng không thể cạnh tranh vị trí thống trị của LinkedIn. Cũng như eBay, LinkedIn đã biên cả một ngành công nghiệp trước đây chỉ dựa trên giấy tờ thành một chợ điện tử hiệu quả. LinkedIn giờ đã trở thành một nền tảng việc làm. Theo nghiên cứu mới nhất của công ty phần mềm tuyển dụng Bullhorn, 98,% những nhà tuyển dụng sử dụng mạng xã hội để tìm kiếm những ứng viên tiềm năng, và 97,4% họ sử dụng LinkedIn. Điều này cũng có nghĩa là LinkedIn đã có gần như 100% thị phần. LinkedIn IPO tháng 5 năm 2011 với giá 45 USD / cổ phiếu và đến nay, giá cổ phiếu của LinkedIn là 156 USD, tăng gấp gần 4 lần chỉ trong chưa đầy 2 năm.
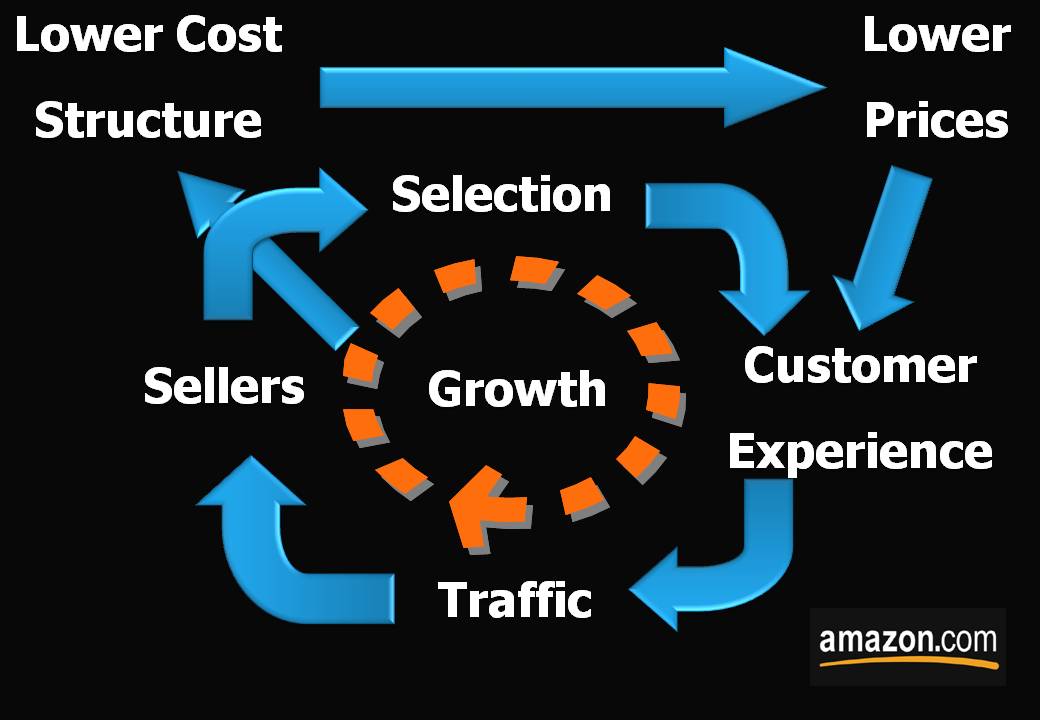
Amazon khởi đầu là một nhà bán sách trực tuyến. Sau này công ty đã phát triển cơ sở hạ tầng của riêng mình để tập trung cho thương mại điện tử. Đầu tiên, Amazon giới thiệu công cụ One Click, giúp người dùng đặt mua chỉ bằng một cú nhấn chuột. Công cụ này là một phần thiết yếu trong hệ thống thương mại điện tử của Amazon. Sau đó, Amazon phát triển một cơ sở hạ tầng rộng lớn hơn, dành cho tất cả các doanh nghiệp kỹ thuật số, không chỉ thương mại điện tử, mang tên Amazon Web Services. Dịch vụ này ban đầu chỉ với mục đích hỗ trợ cho Amazon, nhưng sau khi mở rộng ra, đến nay Amazon Web Services được dự đoán mang về doanh thu 2 tỷ USD hàng năm, và tính đến năm 2016 ước tính doanh thu Amazon Web Services mang về sẽ là 10 tỷ USD hàng năm. Với dịch vụ web, host và lưu trữ, Amazon trở nền một nền tảng, là xương sống cho các startup công nghệ khác như Dropbox. Amazon đã từ một công ty bán sách trực tuyến trở thành một công ty nền tảng. Và từ khi IPO tháng 5 năm 1997 với giá 1,5 USD/ cổ phiếu, đến nay giá trị cổ phiếu của công ty là 260 USD, tăng đến hơn 17.000%.
eBay là công ty đầu tiên và cũng là công ty thành công nhất khi chuyển đổi ngành công nghiệp rao vặt thành một mảng kinh doanh trị giá 74 tỷ USD. Câu chuyện của eBay cũng tương tự như Amazon. Để hỗ trợ mảng kinh doanh chính, eBay đã mua lại công cụ thanh toán điện tử PayPal tháng 7 năm 2002 với giá 1,5 tỷ USD. Ngày nay, tổng giá trị giao dịch qua PayPal là 14 tỷ USD, gấp 3 lần so với năm ngoái, và chiếm đến 39% doanh thu của eBay, tức là 19% thương mại điện tử toàn cầu. Từ một trang đấu giá giữa các cá nhân, eBay giờ đây đã trở thành một chợ điện tử và một nền tảng thanh toán di động. Từ khi IPO đến nay, giá cổ phiếu của eBay đã tăng 7.000%.
Google, nền tảng tìm kiếm và quảng cáo, giờ đây đã có cả một hệ sinh thái. Thị phần của hệ sinh thái này phụ thuộc khá nhiều vào các đối tác như Samsung, như trước đây Microsoft đã thành công với các đối tác Dell, Intel, HP và IBM. Google trở đây đã có hệ điều hành di động có thị phần lớn nhất thế giới. Thực tế, giờ đây Google có thể được coi như 2 công ty: Tìm kiếm và Hệ điều hành di động. Và cả 2 công ty này đều hoạt động như nền tảng vậy. Ở mảng tìm kiếm, đối thủ của Google là Facebook và Microsoft, và ở di động là Apple. Nhưng tại thời điểm hiện tại, Google vẫn đang là người chiến thắng ở cả 2 mảng. Từ khi IPO đến nay, giá cổ phiếu của Google đã tăng 830%.
Facebook kết nối những con người với nhau, và là người tiên phong trong lĩnh vực mạng xã hội. Giờ đây, thách thức của Facebook là mang thêm một điều gì đó đặc biệt hơn, cá nhân hóa hơn cho người dùng. Hãy tưởng tượng đến iOS và việc bị Android giành mất thị phần. Điều tương tự cũng có thể sẽ xảy đến với Facebook khi mà hàng loạt các mạng xã hội riêng tư, hay những mạng xã hội tập trung vào sở thích đang liên tục xuất hiện. Đến nay, Facebook vẫn chưa thể chuyển đổi từ một mạng xã hội kết nối bạn bè sang một nền tảng hay một cơ sở hạ tầng. Facebook đang cố gắng thực hiện điều này bằng Facebook Search và Facebook Pages dành cho các công ty. Với thực tế là chưa thể tạo nên được một nền tảng riêng cho mình, giá cổ phiếu của Facebook đã giảm 28% kể từ khi IPO.
Rõ ràng, những công ty đã tạo được một nền tảng cơ sở hạ tầng của riêng mình đã mang lại những giá trị lớn cho nhà đầu tư. Và chính những công ty ấy mới là những công ty mà các nhà đầu tư mong muốn trong dài hạn, thay vì những thành công ngắn hạn của các công ty chỉ tập trung giải quyết 1 nhu cầu.
Theo Genk
Google muốn Chrome OS thống trị PC  Giám đốc Tài chính kiêm Phó chủ tịch cấp cao Patrick Pichette của Google hy vọng hệ điều hành Chrome OS của hãng này sẽ có được địa vị trên thị trường máy tính như của nền tảng Android ở lãnh địa di động hiện nay. Tại cuộc hội thảo do Morgan Stanley tổ chức hôm nay, trước câu hỏi của cử tọa...
Giám đốc Tài chính kiêm Phó chủ tịch cấp cao Patrick Pichette của Google hy vọng hệ điều hành Chrome OS của hãng này sẽ có được địa vị trên thị trường máy tính như của nền tảng Android ở lãnh địa di động hiện nay. Tại cuộc hội thảo do Morgan Stanley tổ chức hôm nay, trước câu hỏi của cử tọa...
Tin liên quan
 Sony tham gia sản xuất điện thoại Firefox
Sony tham gia sản xuất điện thoại Firefox Các đại gia công nghệ đang muốn học mô hình lãnh đạo của Facebook?
Các đại gia công nghệ đang muốn học mô hình lãnh đạo của Facebook? Google+ trở thành mạng xã hội số 2 thế giới
Google+ trở thành mạng xã hội số 2 thế giới Hacker đấu tranh cho tự do internet tự vẫn, giới công nghệ nổi sóng
Hacker đấu tranh cho tự do internet tự vẫn, giới công nghệ nổi sóng Vì sao các đại gia công nghệ liên tiếp thay CEO
Vì sao các đại gia công nghệ liên tiếp thay CEO Vắng Google, Windows Phone vẫn sống khỏe
Vắng Google, Windows Phone vẫn sống khỏe
 Oracle "chắp cánh" cho dịch vụ điện toán đám mây
Oracle "chắp cánh" cho dịch vụ điện toán đám mây Google Apps sẽ không cho đăng ký miễn phí
Google Apps sẽ không cho đăng ký miễn phí Những xu hướng công nghệ hái ra tiền trong năm tới.
Những xu hướng công nghệ hái ra tiền trong năm tới. ĐH Bách Khoa TP HCM đứng đầu cuộc thi An toàn thông tin
ĐH Bách Khoa TP HCM đứng đầu cuộc thi An toàn thông tin Sony và Panasonic "không có cơ may nhận đầu tư"
Sony và Panasonic "không có cơ may nhận đầu tư" Diện mạo hệ điều hành Firefox OS cho smartphone
Diện mạo hệ điều hành Firefox OS cho smartphone Google nâng tầm Gemini với khả năng tạo video dựa trên AI08:26
Google nâng tầm Gemini với khả năng tạo video dựa trên AI08:26 Google ra mắt công cụ AI cho phép tạo video từ văn bản và hình ảnh00:45
Google ra mắt công cụ AI cho phép tạo video từ văn bản và hình ảnh00:45 TikTok Trung Quốc lần đầu công bố thuật toán gây nghiện02:32
TikTok Trung Quốc lần đầu công bố thuật toán gây nghiện02:32 Giá iPhone sẽ tăng vì một 'siêu công nghệ' khiến người dùng sẵn sàng móc cạn ví00:32
Giá iPhone sẽ tăng vì một 'siêu công nghệ' khiến người dùng sẵn sàng móc cạn ví00:32 Apple muốn tạo bước ngoặt cho bàn phím MacBook05:51
Apple muốn tạo bước ngoặt cho bàn phím MacBook05:51 Tính năng tìm kiếm tệ nhất của Google sắp có trên YouTube09:14
Tính năng tìm kiếm tệ nhất của Google sắp có trên YouTube09:14 Chiếc iPhone mới thú vị nhất vẫn sẽ được sản xuất tại Trung Quốc00:36
Chiếc iPhone mới thú vị nhất vẫn sẽ được sản xuất tại Trung Quốc00:36 Điện thoại Samsung Galaxy S25 Edge lộ cấu hình và giá bán "chát"03:47
Điện thoại Samsung Galaxy S25 Edge lộ cấu hình và giá bán "chát"03:47Tiêu điểm
 Cách Trung Quốc tạo ra chip 5nm không cần EUV
Cách Trung Quốc tạo ra chip 5nm không cần EUV HyperOS 3 sẽ thổi luồng gió mới cho thiết bị Xiaomi
HyperOS 3 sẽ thổi luồng gió mới cho thiết bị Xiaomi Dấu chấm hết cho kỷ nguyên smartphone LG sau 4 năm 'cầm cự'
Dấu chấm hết cho kỷ nguyên smartphone LG sau 4 năm 'cầm cự' Apple Maps hỗ trợ chỉ đường qua CarPlay tại Việt Nam
Apple Maps hỗ trợ chỉ đường qua CarPlay tại Việt Nam Giới công nghệ 'loạn nhịp' vì khái niệm AI PC
Giới công nghệ 'loạn nhịp' vì khái niệm AI PC One UI 7 kìm hãm sự phổ biến của Android 15?
One UI 7 kìm hãm sự phổ biến của Android 15? Thêm lựa chọn sử dụng Internet vệ tinh từ đối thủ của SpaceX
Thêm lựa chọn sử dụng Internet vệ tinh từ đối thủ của SpaceXTin đang nóng


 Rùng mình cách binh sĩ xưa giải quyết "sinh lý", đáng thương nhất là người này
Rùng mình cách binh sĩ xưa giải quyết "sinh lý", đáng thương nhất là người này
 Nam danh hài hơn mẹ vợ 2 tuổi, ở nhà mặt tiền trung tâm quận 5 TP.HCM, có 3 con riêng
Nam danh hài hơn mẹ vợ 2 tuổi, ở nhà mặt tiền trung tâm quận 5 TP.HCM, có 3 con riêng Kỳ Duyên tranh cãi khi mặc áo Đoàn đeo khăn quàng đỏ, liền lên tiếng, gỡ hết ảnh
Kỳ Duyên tranh cãi khi mặc áo Đoàn đeo khăn quàng đỏ, liền lên tiếng, gỡ hết ảnh Nữ BTV có pha xử lý cực tinh tế khi phỏng vấn em bé trên sóng trực tiếp sau lễ diễu binh, diễu hành 30/4
Nữ BTV có pha xử lý cực tinh tế khi phỏng vấn em bé trên sóng trực tiếp sau lễ diễu binh, diễu hành 30/4 Truyền thông quốc tế ấn tượng về đại lễ 30-4 của Việt Nam
Truyền thông quốc tế ấn tượng về đại lễ 30-4 của Việt NamTin mới nhất

Dòng iPhone 17 Pro 'lỡ hẹn' công nghệ màn hình độc quyền

Kế hoạch đầy tham vọng của Apple
Chiếc iPhone mới thú vị nhất vẫn sẽ được sản xuất tại Trung Quốc

Chuẩn USB từng thay đổi cả thế giới công nghệ vừa tròn 25 tuổi
Tính năng tìm kiếm tệ nhất của Google sắp có trên YouTube

Làm chủ chế độ PiP của YouTube với 3 thủ thuật ít người biết

Bot AI Facebook nhập vai người nổi tiếng nói chuyện tình dục với trẻ em

Sau Internet và iPhone, dự đoán của Kurzweil khiến chúng ta phải giật mình

Màn hình Always On là kẻ thù gây hao pin điện thoại?

Android 16 sắp có thể 'chặn đứng' thiết bị USB độc hại
Microsoft đưa tính năng Recall gây tranh cãi trở lại PC Copilot+
Gmail cho iPhone vừa được Google 'lột xác' sau 4 năm
Có thể bạn quan tâm

Con gái minh tinh Hollywood công khai gia nhập 'giới cầu vồng', visual cỡ nào?
Sao âu mỹ
23:20:55 30/04/2025
Nữ nghệ sĩ cực viral sau lễ diễu binh, diễu hành 30/4, xem video xong ai cũng rưng rưng nghẹn ngào
Sao việt
23:06:00 30/04/2025
Nam ca sĩ tuổi 52 tái hôn với tình trẻ
Sao châu á
22:57:10 30/04/2025
Cận cảnh sedan hạng sang Hongqi H9 thế hệ mới vừa ra mắt
Ôtô
22:30:33 30/04/2025
Hàng 'hot' Yamaha 135LC Fi 2025 nhập khẩu về Việt Nam, giá không rẻ
Xe máy
22:21:47 30/04/2025
3 con giáp ôm trọn 300 tỷ vào ngày 30/4/2025, bản mệnh dát vàng, mua nhà sắm xe, làm gì cũng thuận, sung túc đủ đầy
Trắc nghiệm
22:17:33 30/04/2025
Microsoft cảnh báo sẽ khởi kiện nếu bị yêu cầu ngừng dịch vụ đám mây tại châu Âu
Thế giới
22:16:08 30/04/2025
Biển người đổ về phố đi bộ Nguyễn Huệ vui chơi trong tối 30/4
Tin nổi bật
21:31:47 30/04/2025
Họa tiết hoa lá trong tủ đồ mùa hè
Thời trang
21:18:32 30/04/2025
Na tra 2 thu 53k tỷ, hé lộ thời điểm ra mắt phần 3, danh tính đạo diễn gây sốt
Phim châu á
20:55:58 30/04/2025
 Nguyên Trưởng Công an huyện Trà Ôn báo cáo gì vụ tai nạn của con gái nghi phạm bắn người?
Nguyên Trưởng Công an huyện Trà Ôn báo cáo gì vụ tai nạn của con gái nghi phạm bắn người? CQĐT VKSND Tối cao vào cuộc vụ tai nạn liên quan con gái nghi phạm bắn người rồi tự sát
CQĐT VKSND Tối cao vào cuộc vụ tai nạn liên quan con gái nghi phạm bắn người rồi tự sát Những khiếu nại của người cha vụ nữ sinh tử vong ở Vĩnh Long
Những khiếu nại của người cha vụ nữ sinh tử vong ở Vĩnh Long Bộ Công an thẩm tra lại vụ tai nạn khiến bé gái 14 tuổi ở Vĩnh Long tử vong
Bộ Công an thẩm tra lại vụ tai nạn khiến bé gái 14 tuổi ở Vĩnh Long tử vong Người cha đòi lại công lý cho con gái, tự tay bắn tài xế xe tải rồi tự kết thúc
Người cha đòi lại công lý cho con gái, tự tay bắn tài xế xe tải rồi tự kết thúc

 Nữ cảnh sát tranh thủ cõng con trên vai trong giờ nghỉ tập duyệt binh
Nữ cảnh sát tranh thủ cõng con trên vai trong giờ nghỉ tập duyệt binh
 Hoa hậu Kỳ Duyên nói 'rất buồn' và tháo gỡ video gây tranh cãi
Hoa hậu Kỳ Duyên nói 'rất buồn' và tháo gỡ video gây tranh cãi