Tại sao người ta lại dạy AI chơi game?
 PUBG Mobile: Thì ra xe nổ hết bánh, xịt lốp vẫn có thể chạy bon bon nếu bạn áp dụng theo cách này
PUBG Mobile: Thì ra xe nổ hết bánh, xịt lốp vẫn có thể chạy bon bon nếu bạn áp dụng theo cách này Switchblade – Game đua xe MOBA đầu tiên trên thế giới
Switchblade – Game đua xe MOBA đầu tiên trên thế giớiGame đã được chứng minh là một phần quan trọng trong nghiên cứu AI, tất cả đều để phục vụ khoa học.
OpenAI, phòng thí nghiệm nghiên cứu trí tuệ nhân tạo được thành lập bởi Sam Altman và Elon Musk, gần đây đã tuyên bố sẽ gửi một đội đến Vancouver vào tháng 8 để tham gia một giải đấu chuyên nghiệp của tựa game online nổi tiếng DOTA 2. Nhưng không giống như các đội khác sẽ cạnh tranh cho giải thưởng nhiều triệu đô la, nhóm của OpenAI sẽ không liên quan đến con người, ít nhất là không trực tiếp.
Được gọi là OpenAI Five, bao gồm năm neural network nhân tạo đã được “tôi luyện” thông qua sức mạnh tính toán khổng lồ của đám mây Google và thực hành trò chơi hàng ngàn, hàng triệu lần. OpenAI Five đã thực sự là vô địch trong Dota 2 bán chuyên và sẽ tiếp tục thử nghiệm khả năng của nó với những top 1% game thủ hàng đầu vào tháng Tám năm nay.

Theo tờ New York Times, OpenAI đang được hoạt động cùng một số nhà khoa học hàng đầu thế giới về AI, với mức lương họ kiếm được là hàng triệu đô la. Xét cho cùng, không viết rằng liệu họ có thể làm việc để ứng dụng AI trên những vấn đề quan trọng hơn, chẳng hạn như phát triển AI có thể chống lại ung thư hoặc khiến những chiếc xe tự lái an toàn hơn không?
Thoạt nhìn, việc chi tiêu tài nguyên máy tính đắt tiền và quy tụ các tài năng AI hàng đầu để dạy AI chơi game có vẻ vô ích. Vô lý hơn khi có vẻ như một số trò chơi đã được chứng minh là một phần quan trọng trong nghiên cứu AI. Từ môn cờ vua nhẹ nhàng đến game khủng DOTA 2, mỗi khi AI đã chinh phục được một trò chơi, nó đã giúp chúng ta phá vỡ nền tảng mới trong khoa học máy tính và các lĩnh vực khác.

Game giúp theo dõi tiến độ của AI
Kể từ khi thành lập ý tưởng về trí thông minh nhân tạo trong những năm 1950, game đã là một cách hiệu quả để đo lường năng lực của AI. Chúng đặc biệt thuận tiện trong việc kiểm tra năng lực của các kỹ thuật AI mới, bởi bạn có thể định lượng hiệu suất của AI với điểm số và thắng-thua và so sánh nó với con người hoặc AI khác.
Trò chơi đầu tiên mà các nhà nghiên cứu cố gắng để làm chủ thông qua AI là cờ vua, là trò mà trong những ngày đầu được coi là thử nghiệm tối thượng của tiến bộ trong lĩnh vực này. Năm 1996, Deep Blue của IBM là máy tính đầu tiên đánh bại một nhà vô địch thế giới (Garry Kasparov) trong môn cờ vua. AI đằng sau Deep Blue sử dụng phương pháp brute-force để phân tích hàng triệu chuỗi lệnh trước khi thực hiện di chuyển.
Tuy nhiên, phương pháp của Deep Blue để làm chủ môn cờ không còn hiệu quả để giải quyết các trò chơi phức tạp hơn. Theo tiêu chuẩn ngày nay, phương pháp đó được xem là thô. Khi Deep Blue đánh bại kiện tướng Kasparov, đã có một nhà khoa học nhận xét rằng sẽ mất thêm một trăm năm nữa để AI có thể chinh phục môn Cờ Vây của Trung Quốc, nổi tiếng với lượng đường đi nhiều hơn cả số lượng nguyên tử trong vũ trụ.
Nhưng trong năm 2016, các nhà nghiên cứu DeepMind – công ty AI thuộc sở hữu của Google – đã tạo ra AlphaGo, AI này đã đánh bại Lee Sedol – nhà vô địch Cờ Vây thế giới – với tỉ số 4-1 trong một cuộc thi năm ván đấu. AlphaGo thay thế phương pháp brute-force của Deep Blue bằng deep learning, một kỹ thuật AI hoạt động theo cách tương tự như cách thức hoạt động của bộ não con người. Thay vì kiểm tra mọi kết hợp có thể, AlphaGo đã kiểm tra cách con người chơi Cờ Vây, sau đó cố gắng tìm ra và nhân rộng các mẫu gameplay thành công.

Video đang HOT
Các nhà nghiên cứu của DeepMind sau đó đã tạo ra AlphaGo Zero, một phiên bản cải tiến của AlphaGo với phương pháp reinforcement learning được sử dụng, một phương pháp không yêu cầu có đầu vào của người. AlphaGo Zero đã được dạy các quy tắc cơ bản của môn Cờ Vây và được học cách chơi game bằng cách tự chống lại chính nó vô số lần. Và AlphaGo Zero đã đánh bại người tiền nhiệm của nó.
Tuy nhiên, các trò chơi trên có những hạn chế nhất định. Đầu tiên, chúng được chơi dựa theo lượt, có nghĩa là AI không bị căng thẳng để đưa ra quyết định trong một môi trường thay đổi liên tục. Thứ hai, AI có quyền truy cập vào tất cả các thông tin trong môi trường và không phải dự đoán hoặc chấp nhận rủi ro dựa trên các yếu tố không xác định.
Xem xét về điều này, một AI được gọi là Libratus đã thực hiện bước đột phá tiếp theo trong nghiên cứu trí tuệ nhân tạo với việc đánh bại những người chơi Texas Hold ‘Em poker giỏi nhất. Được phát triển bởi các nhà nghiên cứu tại Carnegie Mellon, Libratus cho thấy AI có thể cạnh tranh với con người trong những tình huống mà nó chỉ có thể truy cập thông tin một phần. Libratus sử dụng một số kỹ thuật AI để học poker và cải thiện lối chơi của nó khi nó kiểm tra chiến thuật của các đối thủ con người.
Game thời gian thực là ranh giới tiếp theo cho AI và thực tế là OpenAI không phải là tổ chức duy nhất tham gia vào lĩnh vực này. Facebook đã thử nghiệm dạy AI chơi game chiến lược thời gian thực StarCraft, và DeepMind đã phát triển một AI có thể chơi trò chơi bắn súng góc nhìn thứ nhất Quake III. Mỗi trò chơi đều mang các thách thức riêng, nhưng mẫu số chung là tất cả chúng đều thử thách AI với môi trường mà chúng phải đưa ra quyết định trong thời gian thực và thông tin không đầy đủ. Hơn nữa, chúng cung cấp cho AI một đấu trường, nơi AI có thể kiểm tra sức mạnh của nó trong việc chống lại một nhóm đối thủ và tìm hiểu tinh thần đồng đội.
Hiện tại, không ai phát triển AI nhằm đánh bại game thủ chuyên nghiệp. Nhưng thực tế là AI đang cạnh tranh với con người ở những trò chơi phức tạp để cho thấy chúng phát triển đến mức nào.

Game giúp phát triển AI trong các lĩnh vực khác
Trong khi các nhà khoa học đã sử dụng game làm thử nghiệm để phát triển kỹ thuật AI mới, thì thành tích của chúng vẫn không giới hạn chỉ trong các trò chơi. Trên thực tế, AI chơi game đã mở đường cho sự đổi mới trong các lĩnh vực khác.
Năm 2011, IBM đã giới thiệu một siêu máy tính có khả năng xử lý và tạo ngôn ngữ tự nhiên (NLG/NLP) và được đặt theo tên cựu giám đốc điều hành của công ty Thomas J Watson. Siêu máy tính này đã thi đấu hai người chơi giỏi nhất thế giới trong game đố vui Jeopardy trên truyền hình nổi tiếng, và đã giành chiến thắng. Watson sau này trở thành cơ sở cho một dòng dịch vụ AI khổng lồ của IBM trong các lĩnh vực khác nhau bao gồm chăm sóc sức khỏe, an ninh mạng và dự báo thời tiết.
Ngoài ra, DeepMind đang sử dụng kinh nghiệm của mình từ việc phát triển AlphaGo để sử dụng AI trong các lĩnh vực khác, nơi reinforcement learning có thể trợ giúp rất nhiều. Công ty đã đưa ra một dự án với National Grid UK để sử dụng các tính năng của AlphaGo để nâng cao hiệu quả của lưới điện nước Anh. Google, công ty mẹ của DeepMind, cũng đang sử dụng kỹ thuật này để cắt giảm chi phí điện năng của các trung tâm dữ liệu khổng lồ của mình bằng cách tự động hóa việc kiểm soát tiêu thụ phần cứng khác. Google cũng đang sử dụng reinforcement learning để đào tạo rô-bốt mà một ngày nào đó sẽ xử lý các đối tượng này trong các nhà máy.

Libratus, AI chơi poker, có thể giúp phát triển các loại thuật toán có thể giúp trong nhiều tình huống khác nhau như đàm phán chính trị và đấu giá, nơi AI phải chấp nhận rủi ro và hy sinh ngắn hạn cho lợi ích lâu dài.
Chắc hẳn mọi người đang mong chờ được xem OpenAI Five sẽ biểu diễn như thế nào trong cuộc thi Dota 2 tháng Tám. Tôi thì không đặc biệt quan tâm đến việc liệu các neural network và các nhà phát triển của nó có nhận được giải thưởng trị giá 15 triệu đô la hay không. Điều tôi rất muốn xem là những gì mà các cánh cửa thành tựu của nó sẽ mở ra…
Theo GameK
Rules of Survival: 10 tình huống bi hài mà bất cứ game thủ nào cũng ít nhiều gặp phải
Đôi khi việc xử lý một tình huống không tốt trong Rules of Survival sẽ làm trò cười cho cả cộng đồng.
Có rất nhiều tình huống bi hài diễn ra trong Rules of Survival hằng ngày. Đôi khi đó là chiêu trò dàn dựng với mục đích thư giãn của một người hoặc một nhóm bạn chơi cùng nhau, hoặc cũng có khi là do khả năng xử lý tình huống còn non nhưng thậm chí còn bởi nguyên nhân... lỗi game.
Dưới đây là 10 tình huống bi hài nhất trong Rules of Survival mà bất cứ ai chơi game đôi lúc cũng gặp phải. Bạn đã đối mặt với bao nhiêu tình huống như này rồi?
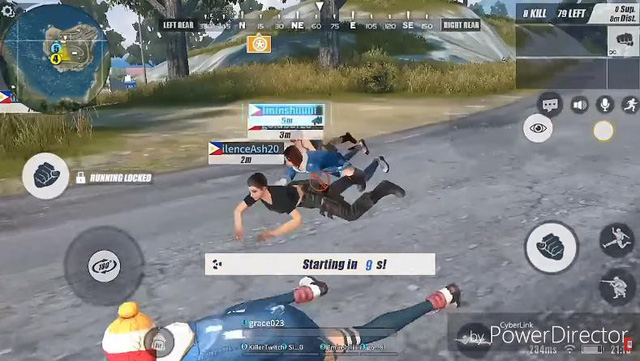
Tổ chức cuộc thi trườn với bạn bè. Nhưng nếu kẻ địch mà nã hỏa tiễn hay súng phóng lựu, hoăn đơn giản là 1 trái lựu đạn thì cả team bỏ mạng cùng nhau là rất cao.
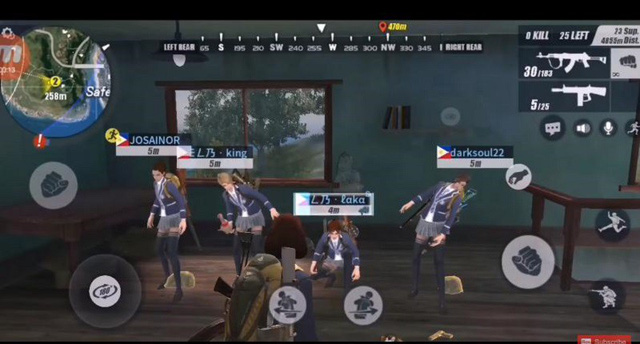
Tổ chức nhảy với các động tác quen thuộc được lặp đi lặp lại như: ngồi, đứng, lắc, nhảy,... với các chiến hữu.
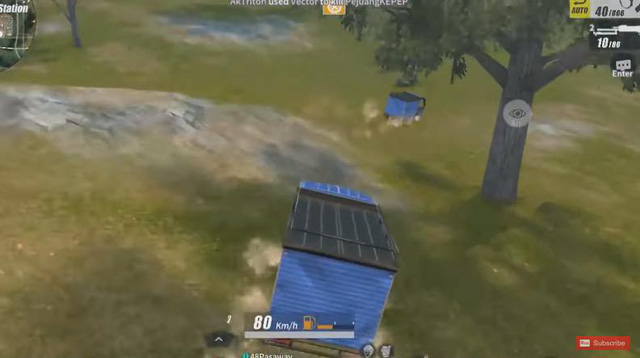
Đua xe với đối phương, biết game bắn súng sinh tồn thành... Fast and Furious.
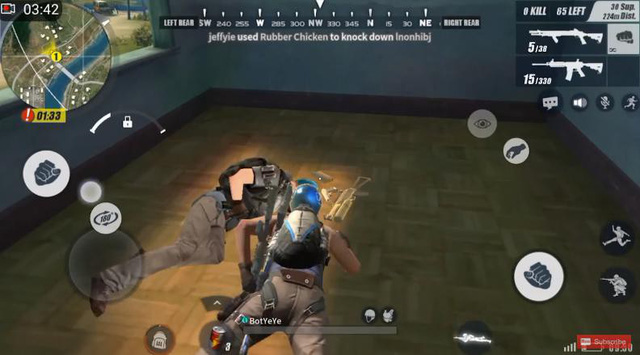
Chơi đùa với... xác của kẻ mà mình vừa hạ gục.
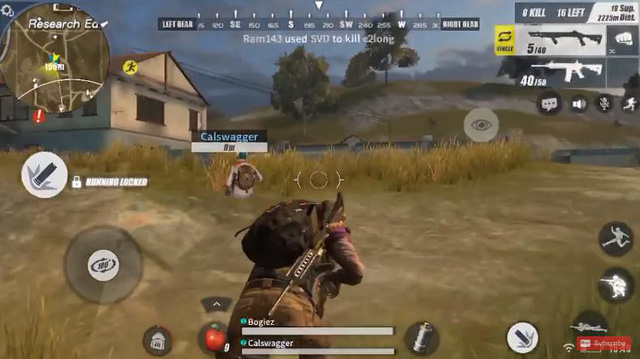
Áp sát theo sau lưng kẻ địch, nhưng không hạ gục ngay mà đợi đối phương... quay lại nhìn mình rồi mới bắn. Một kiểu kết liễu rất khó chịu.
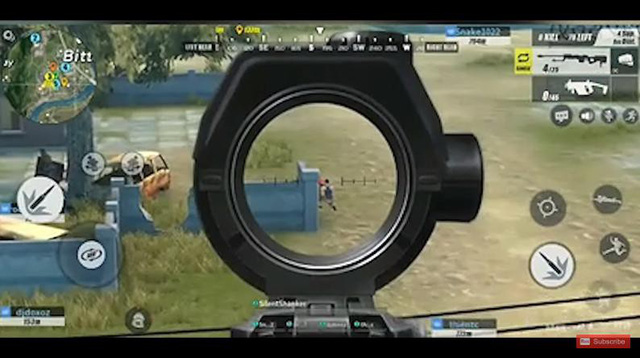
Chủ động ngắm bắn mục tiêu bằng sniper nhưng bắn 3 - 4 phát vẫn không hạ được. Hậu quả là bị dính đòn "hồi mã thương" từ chính "con mồi" mà mình đi săn.
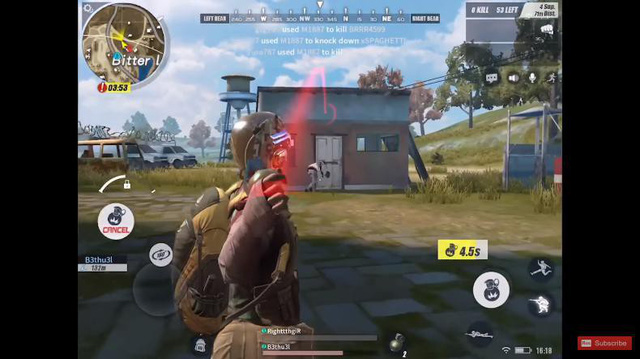
Ném bom vào công trình nghi ngờ có kẻ địch nhưng đối phương không chết mà mình lại... hy sinh trước.
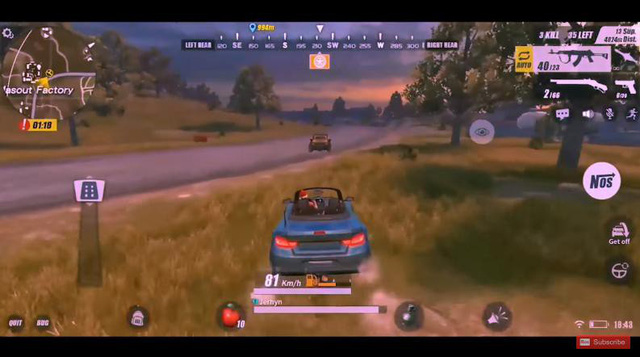
Húc thẳng xe mà mình lái trực diện vào xe của đối phương
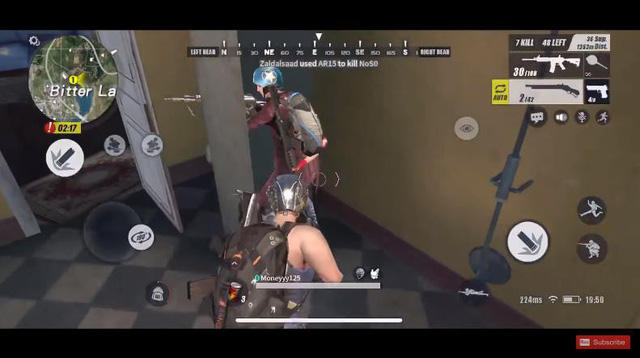
Vào nhà, tới phòng, mở cửa rồi tiêu diệt kẻ địch nấp sau cửa mà không bị thương tổn.

Tàn sát hết đối phương đang tụ tập xung quanh hòm tiếp tế mà chúng không kịp phản công lại
Theo GameK
Set trang bị Long Hồn sắp ra mắt trong Tam Quốc Quần Anh Truyện sẽ có giá... 50 triệu đồng?  BQT tựa game này vẫn chưa hé lộ phương pháp để sở hữu set Long Hồn nhưng cho đến thời điểm này, rất nhiều đồn đoán cho rằng giá trị thực của nó không hề nhỏ chút nào. Nếu như bạn từng vất vả "cày cuốc" chỉ để ghép mảnh từng bộ trang bị cho các tướng chỉ định thì nay, công cuộc...
BQT tựa game này vẫn chưa hé lộ phương pháp để sở hữu set Long Hồn nhưng cho đến thời điểm này, rất nhiều đồn đoán cho rằng giá trị thực của nó không hề nhỏ chút nào. Nếu như bạn từng vất vả "cày cuốc" chỉ để ghép mảnh từng bộ trang bị cho các tướng chỉ định thì nay, công cuộc...
Tin liên quan
 Hướng dẫn cách thiết lập 60fps cho PUBG Mobile chơi được mượt mà trên Android
Hướng dẫn cách thiết lập 60fps cho PUBG Mobile chơi được mượt mà trên Android Chơi game này muốn hiền cũng không được, có những món đồ chỉ mua được bằng "mạng người"
Chơi game này muốn hiền cũng không được, có những món đồ chỉ mua được bằng "mạng người" Free Fire: Không chỉ ban vĩnh viễn account hack, mà thiết bị dùng để gian lận cũng bị cấm luôn
Free Fire: Không chỉ ban vĩnh viễn account hack, mà thiết bị dùng để gian lận cũng bị cấm luôn 5 vị tướng Hỗ Trợ LMHT thích hợp nhất phiên bản 8.6 cho game thủ leo rank dễ dàng
5 vị tướng Hỗ Trợ LMHT thích hợp nhất phiên bản 8.6 cho game thủ leo rank dễ dàng Không chỉ học được cách chơi game, AI này còn "phá" hỏng game bằng một lỗ hổng mà chưa ai tìm ra được
Không chỉ học được cách chơi game, AI này còn "phá" hỏng game bằng một lỗ hổng mà chưa ai tìm ra được
 Hòa Minzy trả lời về con số 8 tỷ đồng làm MV Bắc Bling, cát-xê của Xuân Hinh gây xôn xao04:19
Hòa Minzy trả lời về con số 8 tỷ đồng làm MV Bắc Bling, cát-xê của Xuân Hinh gây xôn xao04:19 Vụ lộ hình ảnh thi hài nghệ sĩ Quý Bình: Nữ nghệ sĩ Việt lên tiếng xin lỗi01:32
Vụ lộ hình ảnh thi hài nghệ sĩ Quý Bình: Nữ nghệ sĩ Việt lên tiếng xin lỗi01:32 Nghẹn ngào khoảnh khắc mẹ diễn viên Quý Bình bật khóc trong giây phút cuối cùng bên con trai00:30
Nghẹn ngào khoảnh khắc mẹ diễn viên Quý Bình bật khóc trong giây phút cuối cùng bên con trai00:30 Đoạn clip của Quý Bình và Vũ Linh gây đau xót nhất lúc này01:32
Đoạn clip của Quý Bình và Vũ Linh gây đau xót nhất lúc này01:32 Trấn Thành rơi vòng vàng và đồng hồ tại Mỹ: "Tôi sợ xanh mặt, cả mớ đó tiền không!"02:09
Trấn Thành rơi vòng vàng và đồng hồ tại Mỹ: "Tôi sợ xanh mặt, cả mớ đó tiền không!"02:09 Cảnh tượng gây bức xúc tại lễ viếng cố nghệ sĩ Quý Bình00:19
Cảnh tượng gây bức xúc tại lễ viếng cố nghệ sĩ Quý Bình00:19 Đám tang diễn viên Quý Bình: Ốc Thanh Vân - Thanh Trúc và các nghệ sĩ Việt đau buồn đến viếng00:30
Đám tang diễn viên Quý Bình: Ốc Thanh Vân - Thanh Trúc và các nghệ sĩ Việt đau buồn đến viếng00:30 Sự cố chấn động điền kinh: VĐV bị đối thủ vụt gậy vào đầu, nghi vỡ hộp sọ02:05
Sự cố chấn động điền kinh: VĐV bị đối thủ vụt gậy vào đầu, nghi vỡ hộp sọ02:05 Lễ tang nghệ sĩ Quý Bình: Xót xa cảnh mẹ nam diễn viên buồn bã, cúi chào từng khách đến viếng00:15
Lễ tang nghệ sĩ Quý Bình: Xót xa cảnh mẹ nam diễn viên buồn bã, cúi chào từng khách đến viếng00:15 Hãy ngừng so sánh Hoà Minzy và Hoàng Thùy Linh, khi nỗ lực đưa bản sắc dân tộc vào âm nhạc đều đi đúng hướng04:19
Hãy ngừng so sánh Hoà Minzy và Hoàng Thùy Linh, khi nỗ lực đưa bản sắc dân tộc vào âm nhạc đều đi đúng hướng04:19 Vụ clip người mặc đồ giống "vua cà phê" Đặng Lê Nguyên Vũ đánh nhau: Trung Nguyên lên tiếng00:17
Vụ clip người mặc đồ giống "vua cà phê" Đặng Lê Nguyên Vũ đánh nhau: Trung Nguyên lên tiếng00:17Tiêu điểm
 Siêu bom tấn 2025 hé lộ thời lượng game khổng lồ, người chơi lại chuẩn bị thay ổ cứng
Siêu bom tấn 2025 hé lộ thời lượng game khổng lồ, người chơi lại chuẩn bị thay ổ cứng Bất ngờ với tựa game có điểm số cao vượt mặt các bom tấn, ứng cử viên "sớm" cho GOTY 2025
Bất ngờ với tựa game có điểm số cao vượt mặt các bom tấn, ứng cử viên "sớm" cho GOTY 2025 Một game di động hấp dẫn giảm giá sâu kỷ lục, giá gốc hơn 200k mà giờ chỉ còn bằng đúng "1 viên kẹo"
Một game di động hấp dẫn giảm giá sâu kỷ lục, giá gốc hơn 200k mà giờ chỉ còn bằng đúng "1 viên kẹo" Mới ra mắt, bom tấn đã nhận mưa lời khen, xứng danh siêu phẩm, rating 96% từ game thủ trên Steam
Mới ra mắt, bom tấn đã nhận mưa lời khen, xứng danh siêu phẩm, rating 96% từ game thủ trên Steam Cựu vương CKTG làm điều chưa từng có trong lịch sử với anti-fan, danh tính "thủ phạm" càng bất ngờ
Cựu vương CKTG làm điều chưa từng có trong lịch sử với anti-fan, danh tính "thủ phạm" càng bất ngờ Hỗ trợ game thủ tới tận răng, "không làm mà vẫn có ăn", bom tấn bị chỉ trích mạnh mẽ, rating siêu tệ trên Steam
Hỗ trợ game thủ tới tận răng, "không làm mà vẫn có ăn", bom tấn bị chỉ trích mạnh mẽ, rating siêu tệ trên Steam Theo trend game bom tấn, nhà hàng Nhật Bản bất ngờ "cháy hàng" một món ăn, bán ngày đêm không xuể
Theo trend game bom tấn, nhà hàng Nhật Bản bất ngờ "cháy hàng" một món ăn, bán ngày đêm không xuể Bom tấn đắt đỏ tiền triệu tiếp tục gặp sự cố khó đỡ, game thủ biến thành "người của tương lai"
Bom tấn đắt đỏ tiền triệu tiếp tục gặp sự cố khó đỡ, game thủ biến thành "người của tương lai"Tin đang nóng


 Vừa nhận lót tay hàng chục tỷ đồng, Thành Chung liền làm một hành động với vợ hotgirl Tuyên Quang, dân tình chỉ biết choáng
Vừa nhận lót tay hàng chục tỷ đồng, Thành Chung liền làm một hành động với vợ hotgirl Tuyên Quang, dân tình chỉ biết choáng Quý Bình và 5 nam nghệ sĩ tài hoa ra đi đột ngột khi tuổi còn xanh
Quý Bình và 5 nam nghệ sĩ tài hoa ra đi đột ngột khi tuổi còn xanh Có một nàng hậu không bao giờ trang điểm
Có một nàng hậu không bao giờ trang điểm Hà Anh Tuấn nhắc kỷ niệm thời hâm mộ, "đốt tiền" vì Lam Trường
Hà Anh Tuấn nhắc kỷ niệm thời hâm mộ, "đốt tiền" vì Lam Trường Song Il Gook (Truyền Thuyết Jumong) bị chất vấn chuyện ăn bám vợ, suốt ngày ngửa tay xin tiền sinh hoạt
Song Il Gook (Truyền Thuyết Jumong) bị chất vấn chuyện ăn bám vợ, suốt ngày ngửa tay xin tiền sinh hoạt Khung ảnh cực hot: Hội bạn F4 Hà thành của Chi Pu - Quỳnh Anh Shyn "kề vai áp má" sau 5 năm chia phe!
Khung ảnh cực hot: Hội bạn F4 Hà thành của Chi Pu - Quỳnh Anh Shyn "kề vai áp má" sau 5 năm chia phe!Tin mới nhất

Một huyền thoại FPS 12 năm tuổi đời chuẩn bị "sống dậy" - từng là "đối chọi" với Đột Kích?

Chơi Genshin Impact trên iPhone 8, game thủ khiến cộng đồng nể phục vì mức độ "nghị lực"

T1 bất ngờ mang "ánh sáng" cho Gumayusi và fan giữa lúc drama vẫn căng thẳng

Giảm giá tới 90%, game bom tấn khiến người chơi ngỡ ngàng, giá chưa bằng hai bát phở

4 năm chờ đợi, cuối cùng bom tấn của NetEase cũng chuẩn bị ra mắt?

Sắp lên PC, bom tấn samurai thế giới mở khiến game thủ "sợ hãi", dung lượng gần 200GB

Có hơn 1 triệu người chơi cùng lúc, bom tấn vẫn tệ kinh khủng, game thủ tự sửa lỗi nhờ "đánh máy lại"

Siêu sao LMHT hết thời than vãn trên stream nhưng nhận ngay cú "phản damage" sâu cay

ĐTCL mùa 13: Thăng hạng thần tốc cùng "đại pháo" Ezreal trong đội hình Vệ Binh - Học Viện

Tựa game giá trị gần 200k được tặng miễn phí, game thủ vẫn ngao ngán, chán nản vì "tặng như không"

Phát hiện một nhân vật "cực bá" trong Genshin Impact, sở hữu khả năng "bất tử" toàn diện khiến game thủ ngỡ ngàng

Bán được 8 triệu bản trong ba ngày, game bom tấn phá kỷ lục, vẫn bị người chơi phàn nàn thậm tệ
Có thể bạn quan tâm

Tuyên bố bất ngờ của Tổng thống Trump về việc chia sẻ thông tin tình báo với Ukraine
Thế giới
15:45:12 10/03/2025
Jennie (BLACKPINK) nói về 6 năm thực tập tại YG: Tàn nhẫn và đau đớn
Nhạc quốc tế
15:37:54 10/03/2025
Giật mình ngã nhào khi gặp xe CSGT, thanh niên dắt xe máy bỏ chạy trối chết để mặc bạn gái đứng bơ vơ giữa đường
Netizen
15:33:04 10/03/2025
Pep Guardiola bí mật bay về Tây Ban Nha mong vợ... hủy ly hôn
Sao thể thao
15:23:16 10/03/2025
9 điểm khiến phim của Ngu Thư Hân, Lâm Nhất "nóng" trước ngày lên sóng
Phim châu á
15:21:04 10/03/2025
Sức mạnh phim độc lập - Từ Oscar 2025 đến sự khơi dậy niềm tin điện ảnh
Hậu trường phim
15:11:27 10/03/2025
Truy sát chém nhau giữa trung tâm TPHCM, một người tử vong
Pháp luật
14:58:37 10/03/2025
Không thời gian - Tập 57: Tâm tỏ tình với thủ trưởng Đại
Phim việt
14:31:55 10/03/2025
Dinh dưỡng cải thiện các triệu chứng của hội chứng Sjgren
Sức khỏe
14:21:30 10/03/2025
Chiều cao gây sốc hiện tại của bộ 3 "em bé quốc dân" Daehan - Minguk - Manse ở tuổi 13
Sao châu á
14:19:33 10/03/2025
 Nuôi đứa con bại não của cô gái quán bia suốt 25 năm, bà bán vé số đau đáu: "Phương ơi, con có còn sống không?"
Nuôi đứa con bại não của cô gái quán bia suốt 25 năm, bà bán vé số đau đáu: "Phương ơi, con có còn sống không?" Lê Phương đăng ảnh nắm chặt tay Quý Bình, nghẹn ngào nói 6 chữ vĩnh biệt cố nghệ sĩ
Lê Phương đăng ảnh nắm chặt tay Quý Bình, nghẹn ngào nói 6 chữ vĩnh biệt cố nghệ sĩ "Cháy" nhất cõi mạng: Tập thể nam giảng viên một trường ĐH mặc váy múa ba lê mừng 8/3, còn bonus cú ngã của Jennifer Lawrence
"Cháy" nhất cõi mạng: Tập thể nam giảng viên một trường ĐH mặc váy múa ba lê mừng 8/3, còn bonus cú ngã của Jennifer Lawrence "Vợ Quý Bình đẫm nước mắt, chỉ xuống đứa bé đứng dưới chân nói: Nè chị, con trai ảnh nè, ôm nó đi chị"
"Vợ Quý Bình đẫm nước mắt, chỉ xuống đứa bé đứng dưới chân nói: Nè chị, con trai ảnh nè, ôm nó đi chị" Lễ an táng diễn viên Quý Bình: Vợ tựa đầu ôm chặt di ảnh, Vân Trang và các nghệ sĩ bật khóc, nhiều người dân đội nắng tiễn đưa
Lễ an táng diễn viên Quý Bình: Vợ tựa đầu ôm chặt di ảnh, Vân Trang và các nghệ sĩ bật khóc, nhiều người dân đội nắng tiễn đưa Nghệ sĩ Xuân Hinh nhắn 1 câu cho Sơn Tùng M-TP mà cả cõi mạng nổi bão!
Nghệ sĩ Xuân Hinh nhắn 1 câu cho Sơn Tùng M-TP mà cả cõi mạng nổi bão! Tang lễ diễn viên Quý Bình: Lặng lẽ không kèn trống, nghệ sĩ khóc nấc trước di ảnh
Tang lễ diễn viên Quý Bình: Lặng lẽ không kèn trống, nghệ sĩ khóc nấc trước di ảnh Học sinh tiểu học tả mẹ "uốn éo trên giường" khiến cư dân mạng ngượng chín mặt: Đọc đến đoạn kết thì ai cũng ngã ngửa
Học sinh tiểu học tả mẹ "uốn éo trên giường" khiến cư dân mạng ngượng chín mặt: Đọc đến đoạn kết thì ai cũng ngã ngửa