Kiến trúc Jaguar – Quân bài dành cho Windows tablet & Ultrabook của AMD
 Appmover: Công cụ tìm kiếm ứng dụng vô cùng đặc biệt trên Android
Appmover: Công cụ tìm kiếm ứng dụng vô cùng đặc biệt trên Android Vô hiệu hóa tính năng tự động đăng nhập ứng dụng trong Windows 8
Vô hiệu hóa tính năng tự động đăng nhập ứng dụng trong Windows 8Dù yếu thế hơn Intel ở dòng chip x86 cao cấp (HP), AMD lại tỏ ra khá mạnh mẽ ở các thiết kế x86 tiết kiệm điện (LP). Hẳn một số bạn vẫn còn nhớ phong trào netbook do Intel khởi xướng hồi 2008 với các cỗ máy dựa trên chip Atom. Điểm khôi hài ở chỗ dù Intel là người đặt ra khái niệm netbook, song AMD mới là người thành công ở dòng máy này khi ra mắt thế hệ APU đầu tiên dựa trên nền tảng Brazos với kiến trúc Bobcat vào 2010. Ba năm sau, hãng này tiếp tục cải tiến dòng sản phẩm x86 LP bằng kiến trúc Jaguar.

Một cái nhìn sơ bộ
Tuy được AMD tiết lộ trước báo giới tại Hot Chips năm nay, song các chip Kabini và Temash dựa trên Jaguar sẽ chưa xuất hiện trong 2012 mà phải tới năm sau mới có mặt trên thị trường. Vì kiến trúc Jaguar được định hướng sản xuất trên dây chuyền 28nm thay cho Bobcat dựa trên 40nm cũ.
Thêm vào đó, những gì AMD công bố lần này chỉ là nhân x86 Jaguar. Còn nhân đồ hoạ dành cho chip Kabini hay Temash vẫn chưa được hé lộ, nhưng nhiều khả năng chúng sẽ dựa trên kiến trúc GCN mà AMD đang áp dụng cho dòng sản phẩm HD 7000 của hãng này. Trong khuôn khổ bài này, chúng ta chỉ đề cập tới nhân Jaguar.

Lộ trình của AMD.
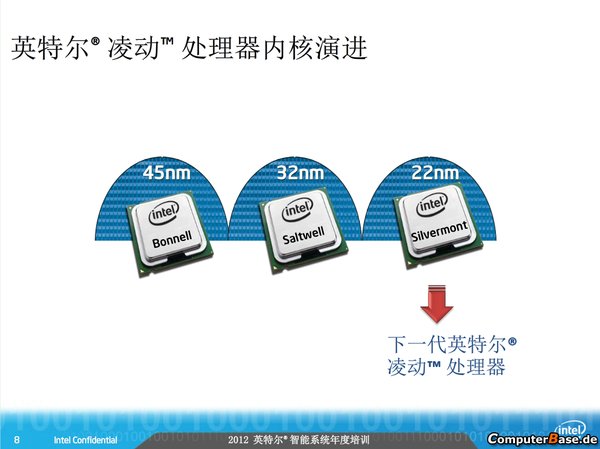
Lộ trình của Intel.
Dù cho kiến trúc Bonnell / Satwell hiện có trên các chip Atom của Intel chưa thực sự tốt, điều này không có nghĩa Intel sẽ không cải thiện chúng. Một số thông tin rò rỉ cách đây không lâu cho thấy các chip Atom 2013 của Intel sẽ dùng kiến trúc Silvermont hứa hẹn sẽ thay đổi cái nhìn về Atom khi chuyển sang chế độ tính toán OoO (out of order) tương tự Bobcat và con chip cao cấp nhất sẽ có tới 4 nhân so với chỉ 2 nhân như hiện nay. Tức AMD không thể hài lòng với những gì Bobcat đang có, họ phải tiếp tục cải thiện chúng.

Jaguar được thiết kế với mục tiêu:
Đem lại hiệu năng cao hơn (thể hiện qua mức IPC)Xung cao hơn trong cùng mức tiêu thụ điệnTiết kiệm điện hơn khi không chạy hết công suấtCó nhiều năng lực tính toán hơn (qua số các tập lệnh cao cấp)
Nhiều năng lực tính toán cho server?
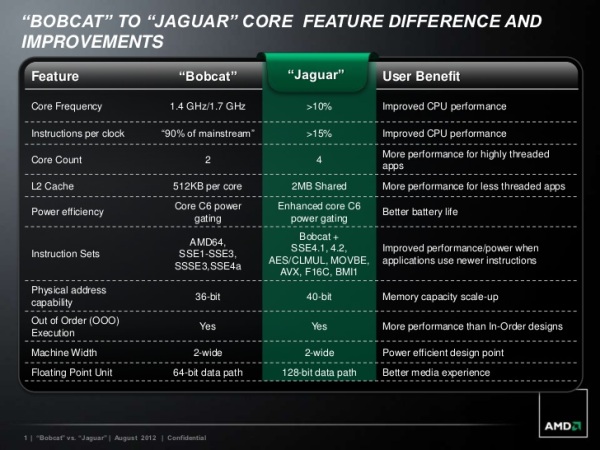
Jaguar vẫn trang bị các tập lệnh (ISA) vốn có trên Bobcat, nhưng kèm thêm các bộ tập lệnh khác hiện chỉ có trên kiến trúc Bulldozer / Piledriver của hãng này, ví như SSE4.1 & 4.2, AES, AVX… Thực sự tôi chưa rõ mục đích của việc này để làm gì vì Jaguar được nhắm đến các thiết kế tiết kiệm điện và không cần hiệu năng quá cao (vốn ngốn nhiều điện). Khó hình dung được có mấy ai dùng chiếc tablet Windows 8 hoặc Ultrabook để chạy render hoặc giải mã AES. Song chọn lựa của AMD là của AMD.

Nền tảng Brazos của AMD cho phép quản lý đến 64 GB bộ nhớ RAM, nhờ năng lực lập địa chỉ bộ nhớ đến 36-bit. Sang tới Jaguar, AMD đẩy con số này lên 40-bit, tức một chip Kabini hay Temash có thể quản lý tới 1 TB (!) Song điều khó hiểu là trên tablet hay Ultrabook thì ai sẽ dùng tới ngần này bộ nhớ? Ngoại trừ việc Jaguar có thể xuất hiện trên server, tôi chưa nghĩ ra được một sản phẩm phổ thông nào cần tới 1 TB RAM.
Sau cùng là năng lực ảo hoá (virtualization). Tính năng này vốn chỉ cần thiết với những ai chạy máy ảo. Dù cho vài người dùng laptop có thể xuất hiện nhu cầu này, song cũng rất hãn hữu. Vẫn hợp lý hơn nếu chạy máy ảo trong môi trường server. Dường như AMD không chỉ nhắm Jaguar cho các thiết bị tiêu dùng cá nhân mà kể cả môi trường doanh nghiệp.
Nâng cao hiệu năng
Việc bổ sung thêm các năng lực tính toán sẽ hoàn toàn vô nghĩa nếu hiệu năng con chip không đổi. Tuy tốt hơn kiến trúc Bonnell của Intel, Bobcat vẫn chưa đủ sức chạy các tác vụ cần nhiều sức mạnh. Dựa theo bảng so sánh của chính AMD, mức xung trên Jaguar sẽ cao hơn Bobcat tối thiểu 10%. So với nền tảng Brazos mạnh nhất có mức xung 1,7 GHz, có thể dự đoán con chip Kabini sẽ đạt mức 2 GHz hoặc trong ngoài khoảng này.
Video đang HOT
Nhưng để có mức xung cao hơn không chỉ là vấn đề overclock (OC), việc này cần đến một vài thay đổi để Jaguar có thể hoạt động ổn định ở mức xung cao. Chúng thay đổi ở bản chất đơn vị xử lý số nguyên INT và số thực FPU.
Nhiều nhân hơn
Tương tự cách làm của Intel với chip Atom Valleyview, AMD cũng cải thiện hiệu năng bằng cách tăng nhiều nhân xử lý hơn. Một chip Kabini sẽ có tối đa 4 nhân Jaguar. Điều này đạt được phần lớn nhờ lợi ích của việc thu nhỏ transistor (từ 40nm xuống 28nm) giúp “nhồi” thêm nhiều trans hơn mà mức tiêu thụ điện không đổi.
Vì có nhiều nhân hơn, AMD áp dụng một phương pháp từng làm với các thiết kế đa nhân trước đây: chia sẻ bộ đệm L2 hoặc L3 Cache nằm giữa chúng. 4 nhân Jaguar sẽ xài chung một bộ đệm L2 Cache 2 MB (trung bình 512 KB mỗi nhân).
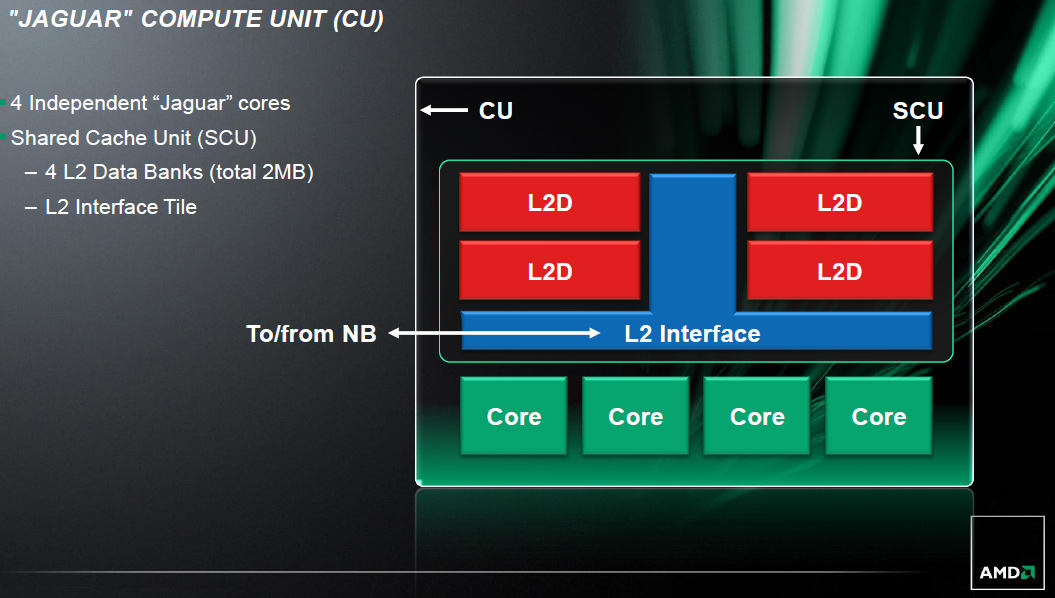
Lợi ích? Nếu một hay nhiều nhân không xài hết phần “của mình”, các nhân còn lại có thể dùng phần “thừa” đó. Cho dễ tưởng tượng, hãy hình dung bạn chia sẻ bàn làm việc với các đồng nghiệp, nếu bạn không dùng hết phần bàn của mình, ai đó có thể hỏi “mượn” để chứa đồ của họ. Thiệt hại? Đôi khi các nhân “rỗi” cần không gian nhớ của riêng nó, sẽ tốn một thời lượng nhất định để các nhân kia “dọn bớt” những gì chúng “lấn chiếm”. Nhưng rõ ràng lợi ích của việc này lớn hơn nên đây có thể xem là một thay đổi hợp lý.
Thay đổi cấu trúc nhân
Nếu so sánh cấu tạo của từng nhân Bobcat và Jaguar (cả INT lẫn FPU), bạn sẽ thấy nhân Jaguar có phần đơn giản hơn. Tuy vậy đây chỉ là hiệu ứng thị giác. Thực ra một số thành phần chức năng đã được AMD “gom” chung thành một đơn vị (có thể thấy ở bên FPU có ít khối chức năng hơn hoặc ở bộ phận front-end).
Thực tế là AMD có bổ sung thêm một số thứ khác vào những gì có sẵn trên Bobcat. Như thêm vào một đơn vị thực hiện các phép chia (Divider) cho nhân INT được thừa hưởng từ chip Llano. Các đơn vị chức năng khác ở INT hoàn toàn không thay đổi (2 ALU, 1 AGU nạp, 1 AGU chứa, 1 bộ nhân). Bên cạnh đó, AMD còn tăng kích thước các đơn vị hỗ trợ xử lý OoO như bộ điều lịch (scheduler) và ROB lớn hơn.
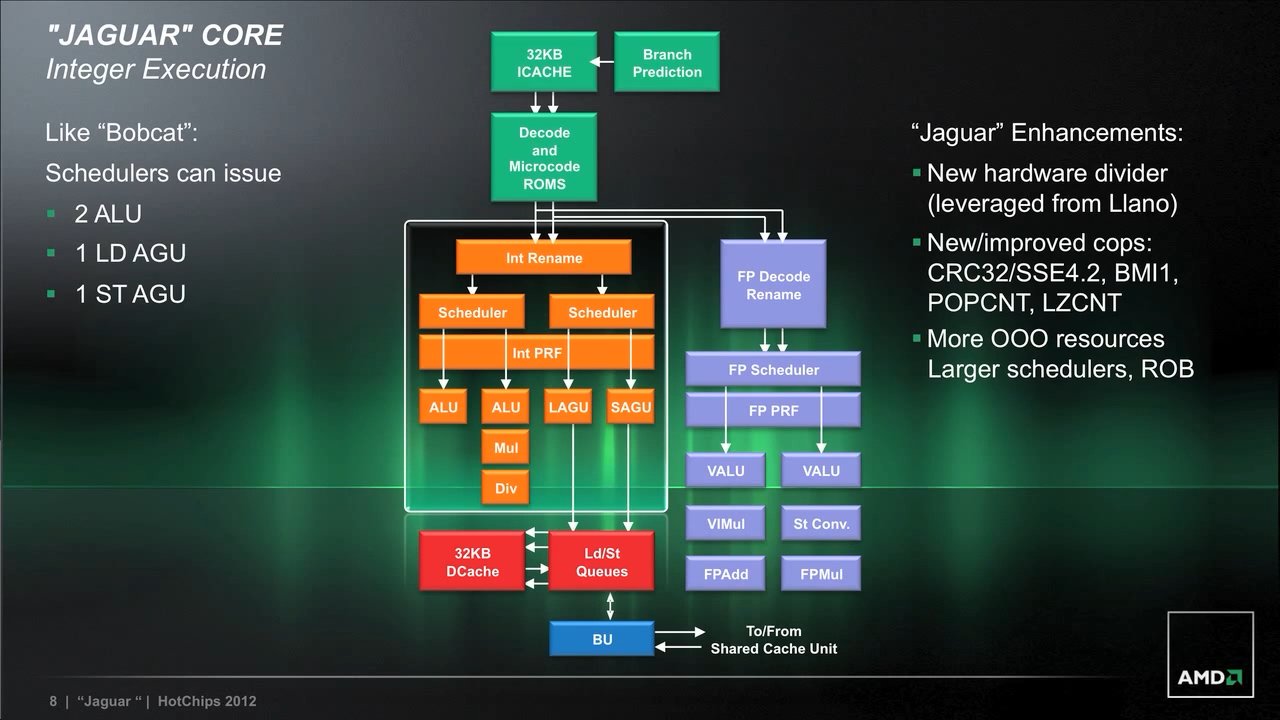
Cấu trúc nhân Jaguar.
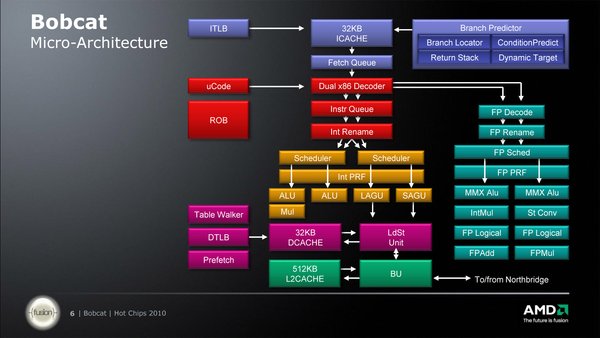
Cấu trúc nhân Bobcat.
Thứ duy nhất bị bỏ đi trên Jaguar mà bạn không thấy trong sơ đồ là L2 Cache. Bởi vì L2 Cache lúc này được dùng chung giữa 4 nhân Jaguar nên nó không thuộc dùng bất kỳ nhân nào. Chỉ có đơn vị BU (bus unit) sẽ giúp 4 nhân này “nói chuyện” với L2 Cache và cầu bắc (north bridge).
Bên cạnh đó, AMD còn bổ sung một thành phần khác tương tự trên Steamroller là một bộ đệm tập lệnh (không nêu trong sơ đồ). Bộ đệm này sẽ lưu lại các tập lệnh được dùng lại nhiều lần (loop) và bộ phận decode có thể được tắt đi để tiết kiệm điện.
Với INT có lẽ không thay đổi nhiều, thì FPU lại có nhiều cải tiến. Các cải tiến này lại không thể hiện trong sơ đồ. Cụ thể là độ rộng các FPU được tăng lên 128-bit, so với mức 64-bit trước đây. Chi tiết này có phần nào trái với dự đoán trước đây của tôi về Jaguar: kiến trúc này không có sự chia sẻ FPU như Bulldozer / Piledriver. Và để tính toán các tập lệnh 256-bit (ví như AVX), một FPU của Jaguar sẽ tốn đến 2 chu kỳ để xử lý (2 x 128-bit). Có nghĩa năng lực FP của Jaguar vẫn không bằng Bulldozer, nhưng dù sao nó vẫn nhanh hơn Bobcat vì kể cả có hỗ trợ AVX, một nhân Bobcat phải tốn tới 4 chu kỳ để xử lý (4 x 64-bit).
Ống lệnh dài hơn, xung cao hơn
Thoạt nghe vài bạn có thể “phản ứng” với cách làm này. Vì sử dụng ống lệnh (pipeline) dài sẽ có nguy cơ bị “thiệt” về hiệu năng nếu cơ chế tiên đoán rẽ nhánh (branch prediction) kém. Đây là điều từng xảy ra trên kiến trúc Netburst của Intel và Bulldozer của AMD. Song không phải cứ làm dài ống lệnh là dở. Vì một số điều sau:
- Ống lệnh dài hơn giúp đạt xung cao hơn. Đây là lý do mà Intel thực hiện với Netburst khi muốn tạo ra con chip 10 GHz! Song cũng là lý do nếu bạn muốn một thiết kế có xung thấp (dưới 2 GHz chẳng hạn) có thể ổn định ở mức cao hơn (giả dụ 3 GHz). Các ống lệnh ngắn khó duy trì mức xung cao ổn định bằng (với cùng lượng trans).

- Sụt hiệu năng là do bộ tiên đoán. Hãy hình dung ống lệnh như một kế hoạch dài hạn, ống lệnh ngắn chỉ thực hiện trong 2 – 3 năm, còn ống lệnh dài từ 5 – 10 năm. Bộ tiên đoán đóng vai trò của ban lãnh đạo ra quyết định sẽ thực hiện gì trong suốt thời gian đó. Nếu lãnh đạo ra quyết định sai thì kế hoạch thực hiện không như ý muốn và ngược lại. Nên hiệu năng cao hay thấp phụ thuộc bộ tiên đoán chứ không phải chiều dài ống lệnh.
- Lợi và hại. Tăng chiều dài ống lệnh có nguy cơ bị hại do tiên đoán sai, song thiệt hại là bao nhiêu so với mức IPC đạt được? Theo AMD, mức IPC mà Jaguar đạt được cao hơn Bobcat đến 15%, trong khi tăng thêm 1 bước cho ống lệnh chỉ gia tăng nguy tiên đoán sai lên 7,7% (13 bước trên Bobcat vs. 14 bước trên Jaguar). Như vậy nhìn chung, tăng chiều dài ống lệnh có lợi trên Jaguar.
Tiết kiệm điện hơn
Thiết kế chip trong hôm nay không chỉ là vấn đề sức mạnh, mà còn là hiệu quả tiêu thụ điện. Một chip đạt 3 GFlops nhưng ngốn 100W vẫn không hiệu quả bằng chip chỉ đạt 2 GFlops mà chỉ xài 50W. Đặc biệt với các thiết bị bị hạn chế về nguồn điện như tablet hay laptop, điều này càng cần thiết hơn. Nên cải thiện hiệu quả tiêu thụ điện cũng là một mục tiêu thiết kế trên Jaguar.

Bằng việc bổ sung / thiết kế lại các bộ đệm tập lệnh (IC Loop Buffer), bộ chứa yêu cầu (Store Queue), L2 Cache có khả năng hạ thấp xung (clock)… kiến trúc Jaguar cho phép dùng điện hiệu quả hơn Bobcat. AMD có một bảng so sánh sau:
Khi không xử lý (halt) cả hai đều không phát sinh IPCKhi xử lý (apps) thì Jaguar đạt 1,1 IPC so với 0,95 IPCKhi chạy các ứng dụng tối ưu cho Bobcat thì mức IPC của cả hai tương đương nhauKhi chạy các ứng dụng tối ưu cho Jaguar thì mức IPC của Bobcat chỉ đạt 1/2
Sơ kết
Nhìn tổng quan, Jaguar là một thiết kế dựa trên Bobcat, nhưng có nhiều cải tiến nhằm giúp kiến trúc mới có thể đạt hiệu năng cao hơn thế hệ cũ. Với tối đa 4 nhân Jaguar, chip Kabini về lý thuyết sẽ hơn hẳn chip Zacate vốn chỉ có 2 nhân Bobcat. Nhờ dây chuyền 28nm, với cùng lượng điện năng tiêu thụ, kiến trúc Jaguar cho phép đạt mức xung cao hơn Bobcat do sản xuất trên 40nm.
Nhưng tất cả các điều trên chỉ đạt được nếu xung của Kabini cao hơn Zacate. Những gì AMD mới trình bày hôm nay chỉ mới hiện trên lý thuyết. Vẫn cần có sản ph ẩm thực tế để kiểm chứng. Và điều này chỉ diễn ra trong năm sau. Sẽ là một câu chuyện thú vị để xem giữa kiến trúc Silvermont của Intel hay Jaguar của AMD tốt hơn.
Theo Genk
Bí ẩn Intel và sự thống trị tuyệt đối thị trường vi xử lý hàng chục năm qua
Tính đến thời điểm bài viết này tới tay độc giả, Intel đã thống trị thị trường vi xử lý toàn cầu trong hơn 20 năm liên tục. Theo một số báo cáo mới được công bố, ngôi vị mà hãng đang sở hữu không có dấu hiệu bị lung lay; trái lại, doanh thu năm tài khóa 2011 của Intel tăng hơn 20%, thị phần của hãng cũng tăng lên mức cao nhất trong 10 năm trở lại đây.

Nền tảng Ivy Bridge (được chính thức giới thiệu vào ngày 23/4 vừa qua) không chỉ đánh dấu sự ra đời của một thế hệ CPU mới, mà còn tiếp tục khẳng định sự vượt trội của Intel so với các đối thủ cạnh tranh trên thị trường vi xử lý toàn cầu. Trong khi TSMC và Global Foundries vẫn đang phải loay hoay với các vấn đề liên quan tới dây chuyền 28/32 nm, Intel cùng các CPU 22nm của mình đã thiết lập rất nhiều kỉ lục mới và tạo nên khoảng cách lớn chưa từng có tiền lệ trong lịch sử ngành công nghiệp này.
Thành công của Intel là sự tổng hợp của rất nhiều nhân tố; trong đó, các yếu tố sản xuất đóng vai trò rất quan trọng. Bài viết dưới đây sẽ phân tích một số điểm đặc biệt trong chiếc lược và công nghệ sản xuất của nhà cung cấp vi xử lý số một thế giới này.
1. Sự kết hợp chặt chẽ giữa R&D (nghiên cứu và phát triển) với quá trình sản xuất
Có thể độc giả sẽ ngạc nhiên, nhưng trên thị trường vi xử lý toàn cầu hiện nay gần như chỉ duy nhất Intel đạt được sự kết hợp trên. Thực tế đó bắt nguồn từ việc các hãng khác thường gặp một trong hai vấn đề: Có lợi thế về nghiên cứu thì không có lợi thế về sản xuất và ngược lại. Lấy ví dụ, bất chấp việc tự sản xuất phần lớn các sản phẩm của mình, Samsung và IBM vẫn phải liên kết với Global Foundries trong quá trình R&D. Một số công ty khác, như Qualcomm, Nvidia, Toshiba, ... sở hữu đội ngũ R&D hùng hậu nhưng lại thuê sản xuất từ các đối tác như TSMC, UMC và Global Foundries.

TSMC - Nvidia, điển hình về mối quan hệ hợp tác trong sản xuất.
Quá trình hợp tác trên mang lại những lợi thế nhất định cho các hãng, như tập trung chuyên môn hóa và nâng cao hiệu quả sản xuất; tuy nhiên một số vấn đề cũng theo đó mà nảy sinh, đặc biệt là những xung đột lợi ích trong quan hệ nhà nghiên cứu - nhà sản xuất. Bên cạnh đó, quá trình chuyển giao công nghệ và cải tiến dây chuyền sản xuất cũng sẽ gặp những khó khăn và độ trễ nhất định. Hơn nữa, khi sản phẩm được chính thức tung ra thị trường, sức ép nâng cao năng suất dẫn tới một số hệ lụy khác: Sản xuất gặp trục trặc, sản lượng sụt giảm, tỉ lệ sản phẩm lỗi tăng cao, ...
Với Intel thì khác, họ làm chủ toàn bộ quá trình sản xuất, qua đó tránh khỏi các bất lợi nêu trên và giải quyết các vấn đề phát sinh một cách nhanh chóng. Ngoài Intel, Global Foundries (hãng vi xử lý được tách ra từ bộ phận sản xuất của AMD trước kia) cũng có đủ tiềm lực để vừa R&D vừa sản xuất, song hãng này không trực tiếp phát triển sản phẩm của riêng mình mà trở thành đối tác nhận nghiên cứu và gia công rất nhiều loại chip của một số hãng khác nhau như AMD, Broadcom, Qualcomm, ...
2. Phương pháp "Copy Exactly" (Sao chép chính xác)
Hiện tại, cũng giống như hầu hết các hãng vi xử lý khác, Intel sở hữu rất nhiều nhà máy sản xuất (fabs) trên toàn cầu; mỗi nhà máy chuyên môn hóa sản xuất một loại kích thước bản nền (wafer) nhất định và các dòng CPU thuộc những nền tảng tương ứng (45, 32, 22 nm, ...). Trong mỗi lần chuyển giao công nghệ, thách thức đặt ra đối với Intel chính là việc đồng bộ hóa quá trình sản xuất tại các nhà máy này nhằm nâng cao năng suất và thỏa mãn nhu cầu của thị trường về những dòng chip mới.

Danh sách các nhà máy (fabs) của Intel.
Để giải quyết vấn đề trên, Intel sử dụng phương pháp Copy Exactly! - phương pháp cho phép nhân bản các mẫu thiết kế chip thành công qua nhiều nhà máy khác nhau. Phương pháp này được Intel phát triển từ cuối những năm 1980, khi hãng gặp trục trặc với nền tảng 0.5 m. Quy trình của Copy Exactly! diễn ra như sau: Đầu tiên, dây chuyền và máy móc sản xuất được sao chép từ các nhà máy có chức năng nghiên cứu như D1C, D1D đến các nhà máy khác; sau đó từng thông số kĩ thuật bao gồm độ ẩm không khí, nhiệt độ phòng, mức hoạt động của bộ lọc gió hay thậm chí ... màu sắc ánh sáng phòng cũng được điều chỉnh y hệt. Hiệu quả của Copy Exactly! được thể hiện qua bảng sau:
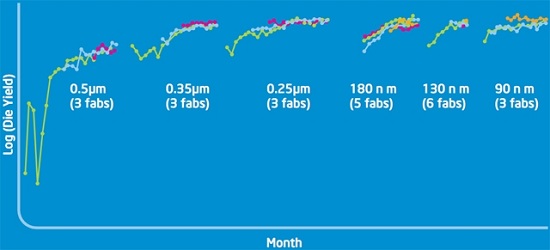
Sản lượng các dòng chip Intel tại từng nhà máy qua các tháng.
Xét đến dây chuyền 0.5 m, đường màu xanh lá cây thể hiện sản lượng chip đạt được tại nhà máy sản xuất đầu tiên - sau một mức đỉnh ngắn, do gặp phải một số trục trặc, sản lượng sụt giảm nhanh chóng và phải mất hàng tháng trời mới khôi phục được. Phải đến khi nhà máy đầu tiên ổn định sản xuất, công nghệ mới được chuyển giao đến nhà máy thứ hai; ở đây, vấn đề lại tiếp diễn, khiến nhà máy này tiếp tục mất thêm một thời gian không nhỏ để khắc phục.
Copy Exactly! không trực tiếp giải quyết các trục trặc mà hệ thống sản xuất gặp phải, nhưng nó đảm bảo các trục trặc đó sẽ không tái diễn tại các nhà máy khác. Hơn nữa, phương pháp này cũng giúp Intel chủ động và linh hoạt hơn trong sản xuất. Các nhà máy của Intel sản xuất cùng lúc nhiều loại chip khác nhau; nếu như có một dây chuyền nào đó gặp vấn đề chưa giải quyết được, nhà máy đó có thể lập tức "chữa cháy" bằng việc sử dụng Copy Exactly! để tập trung vào một sản phẩm khác.
3. Mô hình phát triển Tick-Tock

Mô hình Tick-Tock.
Được giới thiệu vào năm 2007, mô hình Tick-Tock đã trở thành biểu tượng cho sự phát triển mạnh mẽ của Intel những năm vừa qua. Mô hình này giúp Intel kiểm soát và đặt ra lộ trình cho những sự thay đổi trong cấp độ kiến trúc của các sản phẩm vi xử lý.
Theo mô hình Tick-Tock này, một kiến trúc sẽ tồn tại cho 2 thế hệ sản phẩm. Tock: tiến trình sản xuất cũ, kiến trúc mới còn Tick: tiến trình sản xuất mới, kiến trúc cũ. Lấy ví dụ về dòng chip mới nhất mà Intel cho ra mắt: Ivy Bridge. Dòng chip này nằm trong tiến trình Tick - điều đó có nghĩa rằng đây là những CPU được Intel sử dụng kiến trúc cũ (giống với Sandy Bridge) nhưng với tiến trình sản xuất hoàn toàn mới (22 nm).
Mô hình Tick-Tock giúp Intel tổ chức và triển khai công nghệ mới theo một lộ trình ổn định. Điều này mang lại nhiều ích lợi: thứ nhất, rủi ro về hiệu ứng domino khi một tính năng mới đưa vào có thể làm hỏng toàn bộ chu trình thiết kế sẽ được giảm thiểu; thứ hai, đội ngũ kĩ thuật sẽ có một thời gian biểu cụ thể để nghiên cứu và quyết định các cải tiến được áp dụng vào chip mới; thứ ba, lộ trình này tạo được ấn tượng lâu dài và thu hút sự chú ý lớn đối với người tiêu dùng.

Lộ trình phát triển của Tick-Tock.
Dù vậy, do gặp phải những giới hạn vật lý, mô hình Tick-Tock đặt ra những thử thách rất lớn cho Intel. Xét từ năm 2007, chỉ có 2 dòng chip Penryn và Nehalem (cùng 45nm) là được ra mắt đúng với lộ trình này. Bắt đầu từ tiến trình 32nm, Intel đã không giữ vững được mục tiêu trên: các chip Westmere ra mắt vào 2010, Sandy Bridge vào 2011 và nay là Ivy Bridge trong 2012. Nếu đúng theo lộ trình thì các chip 22nm của Intel đã tràn ngập thị trường từ năm ngoái chứ không cần chờ đến năm nay.
Lời kết
Chưa bàn đến ngân sách R&D, quy mô sản xuất hay đội ngũ kĩ thuật hùng hâu; chỉ qua những phân tích trên, có thể thấy thành công của Intel đến như một lẽ tất yếu. Đó là kết quả của sự hợp tác chặt chẽ giữa các nhà thiết kế CPU và các kĩ sư sản xuất, của một quá trình chuyển giao công nghệ hợp lý, của một lộ trình sản xuất tuyệt vời cùng rất nhiều những yếu tố khác nữa. Liệu Intel có tiếp tục thành công với những bước Tick-Tock đến các nền tảng cao hơn, liệu Intel có giữ được ngôi vị thống trị thị trường vi xử lý toàn cầu trong tương lai? Điều đó chưa được kiểm chứng, nhưng ở thời điểm hiện tại, họ đang đi trước toàn bộ ngành công nghiệp những bước dài.
Theo ICTnew
AMD "đại hạ giá" dòng card HD 7000 28nm  Hầu hết các sản phẩm công nghệ sẽ bắt đầu giảm giá bán sau một thời gian ra mắt. Lý do thường gặp nhất là chúng gặp sự cạnh tranh từ đối thủ. Mức giá "mềm" hơn hẳn nhiên sẽ thu hút người tiêu dùng hơn. Với Radeon HD 7000 lần này, mức giảm cao nhất áp dụng cho model HD 7970 lên...
Hầu hết các sản phẩm công nghệ sẽ bắt đầu giảm giá bán sau một thời gian ra mắt. Lý do thường gặp nhất là chúng gặp sự cạnh tranh từ đối thủ. Mức giá "mềm" hơn hẳn nhiên sẽ thu hút người tiêu dùng hơn. Với Radeon HD 7000 lần này, mức giảm cao nhất áp dụng cho model HD 7970 lên...
Tin liên quan
 10 thuật ngữ công nghệ nên biến mất ngay lập tức
10 thuật ngữ công nghệ nên biến mất ngay lập tức Asus khai tử dòng netbook Eee PC
Asus khai tử dòng netbook Eee PC Chip Haswell cho ultrabook của Intel sẽ có TDP chỉ 10W
Chip Haswell cho ultrabook của Intel sẽ có TDP chỉ 10W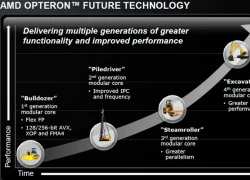 Chip Streamroller: "Thần hộ mệnh" cho tham vọng lật đổ Intel của AMD
Chip Streamroller: "Thần hộ mệnh" cho tham vọng lật đổ Intel của AMD Qualcomm hợp tác với LG để sớm đưa chip Snapdragon S4 Pro ra thị trường
Qualcomm hợp tác với LG để sớm đưa chip Snapdragon S4 Pro ra thị trường Samsung đầu tư 4 tỉ USD vào nhà máy sản xuất chip ở Austin
Samsung đầu tư 4 tỉ USD vào nhà máy sản xuất chip ở Austin
 Chip xử lý Trung Quốc gây nguy hiểm cho Mỹ
Chip xử lý Trung Quốc gây nguy hiểm cho Mỹ nVidia: Sẽ có 30 smartphone lõi tứ ra mắt trong năm nay
nVidia: Sẽ có 30 smartphone lõi tứ ra mắt trong năm nay Toshiba ngưng bán netbook tại Mỹ
Toshiba ngưng bán netbook tại Mỹ Chip "lỗi" cho hiệu quả cao gấp 15 lần chip thường
Chip "lỗi" cho hiệu quả cao gấp 15 lần chip thường Thiết bị chạy hệ điều hành Tizen rục rịch ra mắt
Thiết bị chạy hệ điều hành Tizen rục rịch ra mắt Intel muốn càng nhiều laptop không tản nhiệt càng tốt
Intel muốn càng nhiều laptop không tản nhiệt càng tốt Vợ Giao Heo gục ngã khi biết tin chồng mất, tiết lộ lời hứa dang dở gây xót xa02:33
Vợ Giao Heo gục ngã khi biết tin chồng mất, tiết lộ lời hứa dang dở gây xót xa02:33 Bùi Quỳnh Hoa kiện tài khoản tung clip riêng tư, hé lộ chi tiết sốc02:55
Bùi Quỳnh Hoa kiện tài khoản tung clip riêng tư, hé lộ chi tiết sốc02:55 Trịnh Sảng gặp chuyện vì dính đến Vu Mông Lung, lộ video ai cũng sốc02:41
Trịnh Sảng gặp chuyện vì dính đến Vu Mông Lung, lộ video ai cũng sốc02:41 Đức Phúc lộ bảng điểm ở Intervision 2025, đứng Top 1 vào thẳng chung kết?02:52
Đức Phúc lộ bảng điểm ở Intervision 2025, đứng Top 1 vào thẳng chung kết?02:52 Rò rỉ clip Vu Mông Lung bị hại trước lúc mất, nghi phạm hết chối, mẹ già cầu cứu02:44
Rò rỉ clip Vu Mông Lung bị hại trước lúc mất, nghi phạm hết chối, mẹ già cầu cứu02:44 Rộ tin Lisa (Blackpink) đóng phim Việt qua 1 bức ảnh ở LHP, thực hư ra sao?02:49
Rộ tin Lisa (Blackpink) đóng phim Việt qua 1 bức ảnh ở LHP, thực hư ra sao?02:49 Bão số 8 đổ bộ Trung Quốc, gây mưa lớn ở Việt Nam08:52
Bão số 8 đổ bộ Trung Quốc, gây mưa lớn ở Việt Nam08:52 Ninh Dương Story hủy fanmeeting sau loạt lùm xùm, lý do khiến ai cũng sốc02:55
Ninh Dương Story hủy fanmeeting sau loạt lùm xùm, lý do khiến ai cũng sốc02:55 1 Anh Trai nghi đạo nhạc BTS, giống đến 90%, ARMY phẫn nộ, ê-kíp lên tiếng!02:43
1 Anh Trai nghi đạo nhạc BTS, giống đến 90%, ARMY phẫn nộ, ê-kíp lên tiếng!02:43 Vợ Giao Heo luôn "dạ - thưa", được chồng cưng chiều, 5 năm mất 3 người thân02:52
Vợ Giao Heo luôn "dạ - thưa", được chồng cưng chiều, 5 năm mất 3 người thân02:52 Lisa (BLACKPINK) càn quét LHP Busan, nhận về phản ứng trái chiều vì 1 chi tiết?02:39
Lisa (BLACKPINK) càn quét LHP Busan, nhận về phản ứng trái chiều vì 1 chi tiết?02:39Tiêu điểm
 Apple Watch tích hợp AI phát hiện nguy cơ cao huyết áp
Apple Watch tích hợp AI phát hiện nguy cơ cao huyết áp Với Gemini, trình duyệt Chrome ngày càng khó bị đánh bại
Với Gemini, trình duyệt Chrome ngày càng khó bị đánh bại Cập nhật iOS 26, nhiều người "quay xe" muốn trở về iOS 18
Cập nhật iOS 26, nhiều người "quay xe" muốn trở về iOS 18 Vì sao người dùng Galaxy nên cập nhật lên One UI 8
Vì sao người dùng Galaxy nên cập nhật lên One UI 8 Bước vào kỷ nguyên chuyển đổi số, trí tuệ nhân tạo và robotics
Bước vào kỷ nguyên chuyển đổi số, trí tuệ nhân tạo và robotics Microsoft bị tố "đạo đức giả" khi ngừng hỗ trợ Windows 10
Microsoft bị tố "đạo đức giả" khi ngừng hỗ trợ Windows 10 Các nhà phát triển sử dụng mô hình AI của Apple với iOS 26
Các nhà phát triển sử dụng mô hình AI của Apple với iOS 26 Alibaba tái xuất với định hướng AI sau giai đoạn hụt hơi với thương mại điện tử
Alibaba tái xuất với định hướng AI sau giai đoạn hụt hơi với thương mại điện tửTin đang nóng
 Anh họ sát hại bé gái 8 tuổi rồi nhét vào bao tải phi tang ở góc vườn
Anh họ sát hại bé gái 8 tuổi rồi nhét vào bao tải phi tang ở góc vườn Nữ diễn viên duy nhất bị tố góp mặt trong vụ án của sao nam Tam Sinh Tam Thế
Nữ diễn viên duy nhất bị tố góp mặt trong vụ án của sao nam Tam Sinh Tam Thế Từ khóa mạng xã hội gọi tên Đức Phúc
Từ khóa mạng xã hội gọi tên Đức Phúc Hòa Minzy và các sao Việt vỡ oà khi Đức Phúc vô địch Intervision 2025
Hòa Minzy và các sao Việt vỡ oà khi Đức Phúc vô địch Intervision 2025 Vụ chồng bị phạt tù vì quan hệ với vợ: Quy trình miễn chấp hành án phạt tù
Vụ chồng bị phạt tù vì quan hệ với vợ: Quy trình miễn chấp hành án phạt tù
 Chú rể 72 tuổi kết hôn với cô dâu 27 tuổi, đám cưới ở nơi đặc biệt
Chú rể 72 tuổi kết hôn với cô dâu 27 tuổi, đám cưới ở nơi đặc biệt 2 stage chào sân Anh Trai Say Hi mùa 2: Nhảy đẹp hơn hẳn mùa 1 nhưng nhạc khó "thoát vòng"
2 stage chào sân Anh Trai Say Hi mùa 2: Nhảy đẹp hơn hẳn mùa 1 nhưng nhạc khó "thoát vòng"Tin mới nhất

Camera không thấu kính cho ra hình ảnh 3D

CTO Meta: Apple không cho gửi iMessage trên kính Ray-Bans Display

Google sắp bổ sung Gemini vào trình duyệt Chrome trên thiết bị di động

Trí tuệ nhân tạo: DeepSeek mất chưa đến 300.000 USD để đào tạo mô hình R1

Macbook Air M4 khai phá kỷ nguyên AI, mở ra sức mạnh hiệu năng

Mô hình AI mới dự đoán phản ứng hóa học chính xác nhờ bảo toàn khối lượng

Vì sao iPhone Air bị hoãn bán tại Trung Quốc?
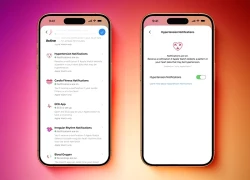
Người dùng Apple Watch đã có thể sử dụng tính năng cảnh báo huyết áp

Cái tên bất ngờ lọt vào top 10 điện thoại bán chạy nhất Quý II/2025
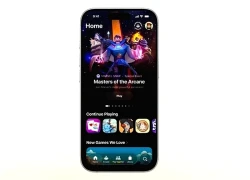
iOS 26 vừa phát hành có gì mới?

Apple nói gì về việc iOS 26 khiến iPhone cạn pin nhanh?

Phát triển AI dự đoán bệnh tật trước nhiều năm
Có thể bạn quan tâm

Dầu quả bơ và dầu ô liu, loại nào tốt hơn cho sức khỏe?
Sức khỏe
20:04:13 21/09/2025
Đột kích quán bar bắt giữ 1 nam ca sĩ quen mặt trong showbiz
Sao châu á
19:58:24 21/09/2025
Cặp đôi "suy đồi" nhất showbiz: Tài tử cặp kè con riêng vợ, sau 3 thập kỷ lên ca ngợi tình yêu gây phẫn nộ
Sao âu mỹ
19:53:55 21/09/2025
Choáng váng trước cảnh tượng bên trong biệt thự 100 tỷ của Huyền Baby
Sao việt
19:48:36 21/09/2025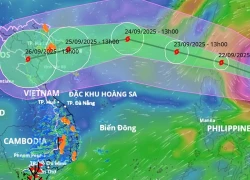
Siêu bão Ragasa vào Biển Đông có thể mạnh như Yagi, tỉnh nào tâm điểm đổ bộ?
Tin nổi bật
19:31:37 21/09/2025
Đúng 6h sáng ngày mai, thứ Hai 22/9/2025, Thần Tài sát cánh, 3 con giáp sau 'ngồi mát ăn bát vàng', lương thưởng tăng lên gấp bội lần, tiêu xài phủ phê
Trắc nghiệm
19:24:34 21/09/2025
Grealish chứng minh Pep đã sai
Sao thể thao
19:19:38 21/09/2025
Nhiều nước chuẩn bị công nhận nhà nước Palestine
Thế giới
19:02:12 21/09/2025
'Gió ngang khoảng trời xanh' tập 19: Lam kiên quyết chia tay Toàn
Phim việt
18:07:00 21/09/2025
Bắt khẩn cấp tài xế tông chết người rồi rời khỏi hiện trường
Pháp luật
16:47:12 21/09/2025
 "Đệ nhất mỹ nhân showbiz" trúng cú lừa thế kỷ của "đại gia rởm", sống ê chề xấu hổ suốt quãng đời còn lại
"Đệ nhất mỹ nhân showbiz" trúng cú lừa thế kỷ của "đại gia rởm", sống ê chề xấu hổ suốt quãng đời còn lại Hoa hậu Nguyễn Thúc Thùy Tiên được áp dụng tình tiết giảm nhẹ
Hoa hậu Nguyễn Thúc Thùy Tiên được áp dụng tình tiết giảm nhẹ Nữ nghệ sĩ sắp lấy chồng lần 3: Là phó viện trưởng, mẹ đơn thân U45 vẫn được đại gia yêu say đắm
Nữ nghệ sĩ sắp lấy chồng lần 3: Là phó viện trưởng, mẹ đơn thân U45 vẫn được đại gia yêu say đắm Diễn biến không ngờ vụ ca sĩ Lynda Trang Đài trộm cắp tài sản
Diễn biến không ngờ vụ ca sĩ Lynda Trang Đài trộm cắp tài sản "Nữ thần thanh xuân" Trần Kiều Ân đòi ly hôn khiến chồng thiếu gia kém 9 tuổi khóc nghẹn
"Nữ thần thanh xuân" Trần Kiều Ân đòi ly hôn khiến chồng thiếu gia kém 9 tuổi khóc nghẹn
 Nữ diễn viên bị tra tấn dã man trong Tử Chiến Trên Không đổi đời nhờ 13 giây hát nhép, cao 3 mét bẻ đôi nhưng đắt giá nhất màn ảnh Việt
Nữ diễn viên bị tra tấn dã man trong Tử Chiến Trên Không đổi đời nhờ 13 giây hát nhép, cao 3 mét bẻ đôi nhưng đắt giá nhất màn ảnh Việt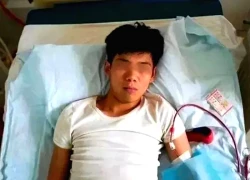 Chàng trai Trung Quốc bán thận để mua iPhone 14 năm trước giờ ra sao
Chàng trai Trung Quốc bán thận để mua iPhone 14 năm trước giờ ra sao Không ngờ cậu nhóc từng gây sốt Vbiz này lại là cảnh vệ điển trai trong Tử Chiến Trên Không, đúng là con trai "ông hoàng phòng vé" có khác!
Không ngờ cậu nhóc từng gây sốt Vbiz này lại là cảnh vệ điển trai trong Tử Chiến Trên Không, đúng là con trai "ông hoàng phòng vé" có khác! Bóng hồng khiến Quán quân Rap Việt bỏ showbiz: Giọng hát gây sốc, tiểu như nhà giàu hậu thuẫn hết mực cho chồng
Bóng hồng khiến Quán quân Rap Việt bỏ showbiz: Giọng hát gây sốc, tiểu như nhà giàu hậu thuẫn hết mực cho chồng