Google trình làng công cụ tìm kiếm tập dữ liệu
 Facebook, Google đang bán rẻ danh dự để quay lại Trung Quốc?
Facebook, Google đang bán rẻ danh dự để quay lại Trung Quốc? Giá trị thương hiệu Samsung tăng gần 60% trong năm 2018
Giá trị thương hiệu Samsung tăng gần 60% trong năm 2018Google đang áp dụng thử nghiệm công cụ tìm kiếm tập dữ liệu cho cộng đồng khoa học.
Công cụ tìm kiếm tập dữ liệu ( Dataset Search ) mới ra mắt của Google được kỳ vọng sẽ trở thành bạn đồng hành hữu hiệu với Google Scholar – công cụ tìm kiếm nghiên cứu và báo cáo học thuật hiện tại. Các viện nghiên cứu của các trường Đại học hay các tổ chức chính phủ khi công bố dữ liệu online sẽ cần thêm các metadata tags (các tags siêu dữ liệu) ở trang web để cung cấp mô tả về dữ liệu, bao gồm các thông tin về tác giả, thời gian công bố, cách thức dữ liệu được thu thập… Những thông tin này sau đó sẽ được sắp xếp lại theo thứ tự thành mục lục trên Dataset Search .
Phát biểu trong bài phỏng vấn của The Verge , Natasha Noy – một nhà khoa học nghiên cứu tại Google AI, người đã góp phần tạo nên Dataset Search – chia sẻ về mục tiêu hợp nhất 10.000 kho dữ liệu online: “Chúng tôi muốn dữ liệu được chia sẻ nhưng không bị di chuyển mà ở nguyên tại nơi đang lưu giữ”.
Hiện tại, các tập dữ liệu công khai khá rời rạc. Mỗi lĩnh vực khoa học khác nhau lại có kho dữ liệu riêng. Điều này xảy ra tương tự với các kho dữ liệu của chính phủ hay chính quyền địa phương. Natasha Noy cho biết thêm: “Các nhà khoa học chia sẻ rằng họ biết chính xác nơi tìm kiếm dữ liệu cho lĩnh vực của họ nhưng không phải lúc nào cũng vậy. Khi bước ra khỏi lĩnh vực thế mạnh của mình, họ sẽ gặp khó khăn”.
Noy lấy ví dụ về cuộc trò chuyện mới đây với một nhà nghiên cứu khí hậu. Cô than phiền với Noy rằng mình đang tìm kiếm tập dữ liệu về nhiệt độ đại dương cho một nghiên cứu sắp tới nhưng không thể thấy. Mãi đến khi tình cờ gặp một người đồng nghiệp ở một buổi hội thảo, cô mới biết dữ liệu mình cần được lưu giữ ở đâu. Cũng chỉ đến lúc đó cô mới có thể tiếp tục nghiên cứu của mình.
“Thậm chí đó không phải là một kho dữ liệu quý hiếm đặc biệt” – Noy nhấn mạnh – “Tập dữ liệu được ghi chép và lưu giữ ở một nơi khá nổi tiếng nhưng vẫn rất khó để tìm thấy”.
Video đang HOT
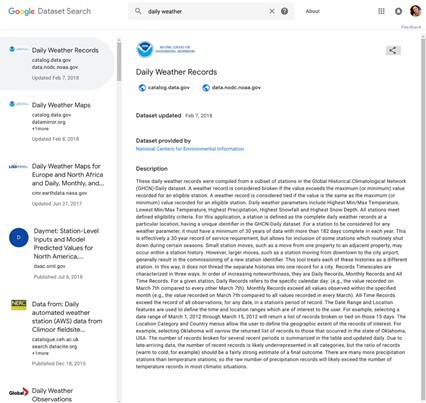
Ví dụ cho kết quả tìm kiếm về báo cáo thời tiết bằng Google Dataset Search
Trong lần ra mắt đầu tiên, Dataset Search sẽ bao gồm các chủ đề khoa học môi trường, khoa học xã hôi, dữ liệu chính phủ và các tập dữ liệu từ những viện tin tức như ProPublica. Tuy nhiên, nếu ứng dụng này trở nên phổ biến, lượng dữ liệu thu thập được sẽ tăng lên nhanh chóng bởi các viện nghiên cứu và các nhà khoa học sẽ tranh nhau chia sẻ thông tin của họ.
Jeni Tennison – CEO của Viện nghiên cứu Dữ liệu mở (ODI) – cho hay: “Tìm kiếm tập dữ liệu luôn khó khăn nhưng tôi hy vọng sự tham gia của Google sẽ giúp điều này trở nên dễ dàng hơn”.
Theo Tennison, để tạo một công cụ tìm kiếm hiệu quả, cần phải nắm rõ hai điều. Thứ nhất là cần xây dựng một hệ thống thân thiện với người dùng. Thứ hai, cần tìm hiểu tâm lý hành vi hay ý định của người dùng khi họ gõ các cụm từ cụ thể để tìm kiếm. Google biết cách thực hiện cả hai điều trên.
Thật vậy, Tennison chia sẻ, lý tưởng nhất là Google sẽ công bố hướng dẫn cách vận hành của Dataset Search. Mặc dù các metadata tags sẽ công khai nguồn dữ liệu được công bố, các công cụ lấy dữ liệu tự động vẫn là một tiêu chuẩn mở, nghĩa là bất kỳ đối thủ nào, ví dụ như Bing hay Yandex, đều có thể phát triển một dịch vụ cạnh tranh. Công cụ tìm kiếm phát triển nhanh nhất chỉ khi một lượng người dùng đáng kể cùng chia sẻ dữ liệu của họ.
“Điều cơ bản và quan trọng nhất là phải hiểu cách mọi người tìm kiếm thông tin” – Tennison nói – “Nếu chúng ta muốn hiểu được cách mọi người tìm kiếm thông tin và khiến thông tin dễ dàng được tìm thấy, sẽ thật tuyệt nếu Google chia sẻ dữ liệu của chính họ về điều này”.
Theo vtv
Công cụ tìm kiếm của Google tại Trung Quốc lưu trữ cả số điện thoại người dùng
Thông tin đáng quan ngại tiếp theo về dự án Dragonfly của Google tiếp tục được The Intercept đăng tải. Một số nguồn tin cho hay, nguyên mẫu công cụ tìm kiếm mà Google xây dựng tại Trung Quốc sẽ lưu trữ cả số điện thoại của người dùng.

Tang web 256.com ghi lại năm 2008, trang web được Google mua lại từ công ty Cai Wensheng.
Theo nguồn tin của The Intercept, Google đã hoàn thành nguyên mẫu của công cụ tìm kiếm mới cho phép chính phủ Trung Quốc kiểm duyệt. Công cụ này sẽ liên kết kết quả với số điện thoại của người dùng để giúp Bắc Kinh dễ dàng theo dõi và truy vấn bất kỳ trường hợp nào vi phạm chính sách của họ.
Công cụ tìm kiếm nói trên nằm trong dự án bí mật có tên Dragonfly cho các thiết bị sử dụng hệ điều hành Android. Hệ thống sẽ tự động xóa các nội dung mà các nhà hành pháp Trung Quốc cho là nhạy cảm, chẳng hạn thông tin chống lại chính phủ nước này, các thông tin về tự do ngôn luận, dân chủ, bình quyền và kêu gọi biểu tình.
Cùng với một số thông tin đã được tiết lộ trước đây về dự án Dragonfly, The Intercept cho rằng để xây dựng "Vạn lý trường thành" trên mạng Internet cho chính phủ Trung Quốc, Google đã biên soạn sẵn một bản danh sách đen các từ khóa bị kiểm duyệt bao gồm: "quyền con người", "sinh viên biểu tình" và "giải thưởng Nobel" bằng tiếng Trung phổ thông.
Các tổ chức hoạt động vì nhân quyền hàng đầu đã chỉ trích gay gắt dự án Dragonfly. Họ cho rằng việc tiếp tay cho Bắc Kinh là hành vi "đồng lõa, vi phạm nhân quyền". Mối quan tâm lớn nhất của các nhà hoạt động nhân quyền không chỉ là vấn đề kiểm duyệt, mà tất cả dữ liệu người dùng trên công cụ tìm kiếm này đều được Google lưu trữ trên cơ sở dự liệu tại Đại lục. Nhờ đó, chính phủ Trung Quốc có thể dễ dàng truy cập, mục tiêu bị nhắm tới thường xuyên là đối tượng hoạt động trong lĩnh vực chính trị và truyền thông.

Ảnh minh họa: TheDailyDot
Chưa kể tới, nguyên mẫu hiện tại được xây dựng có thể liên kết công cụ tìm kiếm trên thiết bị Android với số điện thoại của người dùng. Nhà nghiên cứu Internet cấp cao Cynthia Wong của Tổ chức Theo dõi Nhân Quyền (Human Right Watchs) cho rằng: "Điều này làm nảy sinh vấn đề từ quan điểm về quyền riêng tư, bởi nó sẽ cho phép theo dõi chi tiết và xác định hành vi của mọi người" . Bà Wong nói thêm: "Việc liên kết kết quả tìm kiếm với số điện thoại cụ thể khiến người dùng khó tránh khỏi phương thức giám sát thái quá của chính phủ Trung Quốc".
The Intercept cho biết nhân sự làm việc cho đối tác của Google tại Đại lục được cấp phép để cập nhật danh sách đen các từ khóa bị cấm. Ngoài ra, toàn bộ dữ liệu về thực trạng ô nhiễm không khí đã được thay thế bằng thông tin do một nguồn tin giấu tên của Bắc Kinh cung cấp.Theo bài báo đăng tải trên tạp chí Wall Street Journals, Alphabet (công ty mẹ của Google) sẽ vận hành công cụ tìm kiếm nói trên như một phần của quan hệ hợp tác "liên doanh" với công ty Cai Wensheng. Công ty sở hữu 265.com, trang web được Google mua lại hồi tháng 6/2008, trước khi chính thức tuyên bố rời thị trường tỷ dân vào năm 2010.
Cho tới nay, đã hơn 1 tháng kể từ chi tiết đầu tiên được tiết lộ, Google vẫn tìm cách né tránh các câu hỏi liên quan tới dự án Dragonfly từ các tổ chức nhân quyền, phóng viên và thượng nghị sĩ Mỹ. Đại diện Google nói: "Chúng tôi không bình luận về những suy đoán về các kế hoạch trong tương lai của công ty".
Ngày 13/2 vừa qua, 16 nhà chức trách Mỹ đã bày tỏ mối "quan ngại nghiêm trọng" thông qua bức thư gửi tới Giám đốc điều hành Sundar Pichai và yêu cầu Google công khai kế hoạch về dự án Dragonfly. Đồng thời, nhà nghiên cứu Jack Poulson cùng 4 nhân viên cao cấp của Google đã tuyên bố nghỉ việc.
Trả lời phỏng vấn của The Intercept, ông Poulson thẳng thắn đề cập tới việc công ty đặt lợi nhuận lên trên tôn chỉ hoạt động. Trong bức thư đệ trình lên ban lãnh đạo, ông viết: "Tôi coi yêu cầu khống chế kết quả tìm kiếm, đồng thời chấp nhận sự kiểm duyệt và giám sát để đánh đổi quyền hoạt động tại thị trường Trung Quốc mà ban lãnh đạo Google đã quyết là một sự suy giảm giá trị và vị thế đàm phán của Google với các chính phủ trên toàn cầu".
Theo The Intercept
Google không tiết lộ kế hoạch phát triển công cụ tìm kiếm cho Trung Quốc  Google từ chối trả lời những câu hỏi do nhiều thượng nghị sĩ Mỹ đặt ra về thông tin tập đoàn này đang phát triển một công cụ tìm kiếm chịu sự kiểm duyệt tại Trung Quốc. Một nhóm thượng nghị sĩ Mỹ bao gồm các ông Tom Cotton, Marco Rubio, Robert Menendez, Cory Gardner đầu tháng 8 gửi thư truy vấn lý...
Google từ chối trả lời những câu hỏi do nhiều thượng nghị sĩ Mỹ đặt ra về thông tin tập đoàn này đang phát triển một công cụ tìm kiếm chịu sự kiểm duyệt tại Trung Quốc. Một nhóm thượng nghị sĩ Mỹ bao gồm các ông Tom Cotton, Marco Rubio, Robert Menendez, Cory Gardner đầu tháng 8 gửi thư truy vấn lý...
Tin liên quan
 1.400 nhân viên Google ký tên vào lá thư phản đối kiểm duyệt công cụ tìm kiếm tại Trung Quốc
1.400 nhân viên Google ký tên vào lá thư phản đối kiểm duyệt công cụ tìm kiếm tại Trung Quốc Smartphone của bạn bị giật lag, nhanh nóng và pin tụt nhanh? Có thể máy bạn đã dính mã độc đào tiền ảo rồi
Smartphone của bạn bị giật lag, nhanh nóng và pin tụt nhanh? Có thể máy bạn đã dính mã độc đào tiền ảo rồi Nougat là nền tảng Android phổ biến nhất hiện nay
Nougat là nền tảng Android phổ biến nhất hiện nay Hướng dẫn tắt tính năng theo dõi vị trí trên điện thoại
Hướng dẫn tắt tính năng theo dõi vị trí trên điện thoại Google phát triển AI chống lạm dụng tình dục trẻ em
Google phát triển AI chống lạm dụng tình dục trẻ em Google Chrome tròn 10 tuổi và đang là trình duyệt thống trị
Google Chrome tròn 10 tuổi và đang là trình duyệt thống trị
 Google phát triển AI giúp chống lạm dụng tình dục trẻ em
Google phát triển AI giúp chống lạm dụng tình dục trẻ em Google Chrome tròn 10 năm tuổi!
Google Chrome tròn 10 năm tuổi! Google tăng cường chống lừa đảo hỗ trợ kỹ thuật trực tuyến
Google tăng cường chống lừa đảo hỗ trợ kỹ thuật trực tuyến Loa thông minh AI của Google có thể hiểu, nói chuyện song ngữ cùng lúc
Loa thông minh AI của Google có thể hiểu, nói chuyện song ngữ cùng lúc Trí tuệ nhân tạo mỗi ngày cùng Google
Trí tuệ nhân tạo mỗi ngày cùng Google Trình duyệt Google Chrome tròn 10 năm tuổi
Trình duyệt Google Chrome tròn 10 năm tuổi Tiếc nuối của bản nhạc phim Mưa Đỏ đang gây sốt mạng xã hội04:43
Tiếc nuối của bản nhạc phim Mưa Đỏ đang gây sốt mạng xã hội04:43 Clip bé gái nghèo "giật" đồ cúng cô hồn gây sốt mạng: Gia chủ tiết lộ câu chuyện phía sau00:23
Clip bé gái nghèo "giật" đồ cúng cô hồn gây sốt mạng: Gia chủ tiết lộ câu chuyện phía sau00:23 Vụ 2 anh em làm việc tốt nghi bị đánh dã man ở Bắc Ninh: Camera ghi cảnh trước va chạm01:44
Vụ 2 anh em làm việc tốt nghi bị đánh dã man ở Bắc Ninh: Camera ghi cảnh trước va chạm01:44 BTV Khánh Trang trở lại sau 1 tháng kể từ vụ đọc sai, netizen sốc khi biết lý do02:47
BTV Khánh Trang trở lại sau 1 tháng kể từ vụ đọc sai, netizen sốc khi biết lý do02:47 Thông tin Chính phủ chính thức "điểm mặt" Độ Mixi, nội dung bài viết gây xôn xao02:43
Thông tin Chính phủ chính thức "điểm mặt" Độ Mixi, nội dung bài viết gây xôn xao02:43 Ca sĩ Việt đỗ 3 trường Đại học, du học Mỹ nghề bác sĩ thì bỏ ngang bị mẹ "từ mặt" cả thập kỷ04:30
Ca sĩ Việt đỗ 3 trường Đại học, du học Mỹ nghề bác sĩ thì bỏ ngang bị mẹ "từ mặt" cả thập kỷ04:30 Thương hiệu kinh dị 'trăm tỷ' của Thái Lan - 'Tee Yod: Quỷ ăn tạng' trở lại với phần 3, hứa hẹn kinh dị gấp 3!01:42
Thương hiệu kinh dị 'trăm tỷ' của Thái Lan - 'Tee Yod: Quỷ ăn tạng' trở lại với phần 3, hứa hẹn kinh dị gấp 3!01:42 Clip hot: Sao nhí đắt show nhất Việt Nam dậy thì thành đại mỹ nhân, đứng thở thôi cũng cuốn trôi mọi ánh nhìn00:32
Clip hot: Sao nhí đắt show nhất Việt Nam dậy thì thành đại mỹ nhân, đứng thở thôi cũng cuốn trôi mọi ánh nhìn00:32 Trang Nemo bị chồng chia hết tài sản, giờ tay trắng còn mất quyền nuôi con02:34
Trang Nemo bị chồng chia hết tài sản, giờ tay trắng còn mất quyền nuôi con02:34 Sơn Tùng M-TP càng có tuổi càng hát live dở?03:03
Sơn Tùng M-TP càng có tuổi càng hát live dở?03:03 Lại thêm 1 phim Việt cực cuốn làm khán giả hóng mòn mỏi, nữ chính ai nghe tên cũng nổi da gà00:49
Lại thêm 1 phim Việt cực cuốn làm khán giả hóng mòn mỏi, nữ chính ai nghe tên cũng nổi da gà00:49Tiêu điểm
 17 cách biến ChatGPT thành trợ lý miễn phí
17 cách biến ChatGPT thành trợ lý miễn phí Ngân hàng và dịch vụ tài chính dẫn đầu về ứng dụng AI và GenAI
Ngân hàng và dịch vụ tài chính dẫn đầu về ứng dụng AI và GenAI Samsung ra mắt trợ lý Vision AI tại IFA 2025
Samsung ra mắt trợ lý Vision AI tại IFA 2025 Bạn đã khai thác hết tiềm năng của dữ liệu bán lẻ?
Bạn đã khai thác hết tiềm năng của dữ liệu bán lẻ? Những thách thức trong thương mại hóa 5G ở Việt Nam
Những thách thức trong thương mại hóa 5G ở Việt Nam Nền tảng du lịch trực tuyến chạy đua ứng phó sự trỗi dậy của tác nhân AI
Nền tảng du lịch trực tuyến chạy đua ứng phó sự trỗi dậy của tác nhân AI "Xanh hóa" AI: Nhiệm vụ cấp bách cho Đông Nam Á
"Xanh hóa" AI: Nhiệm vụ cấp bách cho Đông Nam Á OpenAI ký thỏa thuận điện toán đám mây lịch sử trị giá 300 tỷ USD với Oracle
OpenAI ký thỏa thuận điện toán đám mây lịch sử trị giá 300 tỷ USD với OracleTin đang nóng
 3 cái chết nghi thế lực ngầm nhúng tay ở Cbiz: Vụ ngã lầu của "mỹ nam cổ trang" chưa phải kinh hoàng nhất!
3 cái chết nghi thế lực ngầm nhúng tay ở Cbiz: Vụ ngã lầu của "mỹ nam cổ trang" chưa phải kinh hoàng nhất! Nữ NSND vừa lên chức giám đốc nhà hát: Mỹ nhân tài sắc vẹn toàn, chồng cũng là lãnh đạo, rất nổi tiếng
Nữ NSND vừa lên chức giám đốc nhà hát: Mỹ nhân tài sắc vẹn toàn, chồng cũng là lãnh đạo, rất nổi tiếng Tỉnh dậy không mảnh vải che thân, đời tôi bỗng biến thành cơn ác mộng
Tỉnh dậy không mảnh vải che thân, đời tôi bỗng biến thành cơn ác mộng Kim Jong Kook không mời Lee Kwang Soo dự đám cưới, nội bộ Running Man lục đục, cạch mặt nhau?
Kim Jong Kook không mời Lee Kwang Soo dự đám cưới, nội bộ Running Man lục đục, cạch mặt nhau? Nhân chứng vụ 2 anh em bị đánh nhập viện khi cứu người bức xúc lên tiếng
Nhân chứng vụ 2 anh em bị đánh nhập viện khi cứu người bức xúc lên tiếng Hoa hậu Chuyển giới Nong Poy hạnh phúc bên chồng đại gia, ngày càng đẹp
Hoa hậu Chuyển giới Nong Poy hạnh phúc bên chồng đại gia, ngày càng đẹp 5 thói quen buổi sáng giúp kiểm soát cholesterol xấu và bảo vệ tim mạch
5 thói quen buổi sáng giúp kiểm soát cholesterol xấu và bảo vệ tim mạch Ảnh cưới của nam ca sĩ Vbiz và vợ kém 17 tuổi: Visual cô dâu "đỉnh nóc kịch trần", xinh hơn Hoa hậu!
Ảnh cưới của nam ca sĩ Vbiz và vợ kém 17 tuổi: Visual cô dâu "đỉnh nóc kịch trần", xinh hơn Hoa hậu!Tin mới nhất

Ra mắt nền tảng AI hợp nhất 'Make in Viet Nam'

ShinyHunters và các vụ tấn công mạng đánh cắp dữ liệu gây chấn động

NVIDIA và ADI bắt tay thúc đẩy kỷ nguyên robot thông minh

Cần Thơ sẽ có Trung tâm UAV - Robot phục vụ nông nghiệp thông minh
Doanh nghiệp thương mại điện tử, bán lẻ trở thành mục tiêu ưu tiên của hacker

Ra mắt ứng dụng hỗ trợ ra quyết định lâm sàng cho hệ thống y tế tích hợp AI

"Gã khổng lồ" Alibaba phát hành mô hình AI cạnh tranh với OpenAI và Google

Vì sao các tập đoàn công nghệ trả hàng triệu USD để thu hút nhân tài AI?

Tạo đột phá thể chế, thúc đẩy khoa học công nghệ và đổi mới sáng tạo

Khi trí tuệ nhân tạo 'bước vào' phòng phỏng vấn tuyển dụng

Ứng dụng trợ lý ảo hỗ trợ sinh viên trong trường đại học

Meta đối mặt thêm 'sóng gió' từ cáo buộc sai sót trong đảm bảo an ninh mạng
Có thể bạn quan tâm

Tranh cãi thí sinh Miss Grand Vietnam diễn thiết kế trang phục 'bàn thờ', BTC nói gì?
Sao việt
22:08:34 12/09/2025
Hậu chấm dứt quyền bảo hộ, mối quan hệ của Britney Spears với gia đình ra sao?
Sao âu mỹ
22:03:09 12/09/2025
'Soái ca nhí' Gia Khiêm từng gây sốt giờ ra sao?
Nhạc việt
21:56:59 12/09/2025
Khuyến cáo người dùng về bảo mật dữ liệu cá nhân
Tin nổi bật
21:54:33 12/09/2025
Cuộc sống của sao võ thuật Địch Long ở tuổi U.80
Sao châu á
21:51:01 12/09/2025
MU 'tống khứ' thủ môn thảm họa Onana sang Thổ Nhĩ Kỳ
Sao thể thao
21:50:46 12/09/2025
Tranh cãi về vị trí chỗ ngồi tại lễ trao giải Emmy 2025
Hậu trường phim
21:44:55 12/09/2025
Chi tiêu theo ngày hay theo tuần thì lợi hơn? Mẹ Hà Nội 50 tuổi thử cả 2 và bất ngờ với kết quả
Sáng tạo
21:37:04 12/09/2025
Bé 11 tuổi bất ngờ mắc dại vì thú cưng nhà nuôi
Sức khỏe
21:09:51 12/09/2025
Khởi tố 3 nhân viên giao hàng vì tham ô tài sản
Pháp luật
21:05:15 12/09/2025
 Chấn động Cbiz: Rộ tin 1 mỹ nam cổ trang hàng đầu vừa tử vong vì ngã lầu
Chấn động Cbiz: Rộ tin 1 mỹ nam cổ trang hàng đầu vừa tử vong vì ngã lầu Lời khai của bà chủ phòng khám nha khoa Tuyết Chinh hành hung khách hàng
Lời khai của bà chủ phòng khám nha khoa Tuyết Chinh hành hung khách hàng Chấn động vụ "ngọc nữ" bị ông lớn giở đồi bại: Mắc bệnh tâm thần và ra đi trong cô độc ở tuổi 55
Chấn động vụ "ngọc nữ" bị ông lớn giở đồi bại: Mắc bệnh tâm thần và ra đi trong cô độc ở tuổi 55 Rò rỉ ảnh hiện trường nơi "mỹ nam cổ trang số 1 Trung Quốc" ngã lầu tử vong vào sáng nay?
Rò rỉ ảnh hiện trường nơi "mỹ nam cổ trang số 1 Trung Quốc" ngã lầu tử vong vào sáng nay? Hình ảnh cuối cùng của Vu Mông Lung trước khi qua đời vì ngã lầu ở tuổi 37
Hình ảnh cuối cùng của Vu Mông Lung trước khi qua đời vì ngã lầu ở tuổi 37 Tóc Tiên không còn che giấu chuyện dọn khỏi biệt thự?
Tóc Tiên không còn che giấu chuyện dọn khỏi biệt thự? VĐV bóng chuyền Đặng Thị Hồng bị cấm thi đấu vô thời hạn
VĐV bóng chuyền Đặng Thị Hồng bị cấm thi đấu vô thời hạn Vụ "mỹ nam số 1 Trung Quốc" ngã lầu tử vong: Nhân chứng kể lại hiện trường đầy thương tâm
Vụ "mỹ nam số 1 Trung Quốc" ngã lầu tử vong: Nhân chứng kể lại hiện trường đầy thương tâm Bố qua đời sau một ngày nói hiến tạng cho mẹ, bé gái 11 tuổi nghẹn ngào
Bố qua đời sau một ngày nói hiến tạng cho mẹ, bé gái 11 tuổi nghẹn ngào Diễn viên Thiên An bất ngờ tung full tin nhắn làm giấy khai sinh, lần đầu đáp trả về họp báo 2 tiếng
Diễn viên Thiên An bất ngờ tung full tin nhắn làm giấy khai sinh, lần đầu đáp trả về họp báo 2 tiếng