Google chi 9 tỷ USD để trở thành công cụ tìm kiếm mặc định trên trình duyệt của Apple
 Facebook chặn người dùng chia sẻ các tin tức sau sự cố vi phạm dữ liệu
Facebook chặn người dùng chia sẻ các tin tức sau sự cố vi phạm dữ liệu Facebook gửi cảnh báo cho người Việt, thừa nhận bị tấn công
Facebook gửi cảnh báo cho người Việt, thừa nhận bị tấn côngCon số trong thương vụ bạc tỷ này thậm chí có thể tăng thêm nhiều lần vào năm sau.
Việc Google phải thanh toán cho Apple một khoản phí thường niên để có thể trở thành công cụ tìm kiếm mặc định trên Safari cho iPhone và iPad không phải là điều mới mẻ. Thực tế, năm 2014, Google đã trả cho Apple 1 tỷ USD và năm ngoái con số này tăng lên 3 tỷ USD. Theo nhà phân tích Rod Hall, năm nay, thương vụ bạc tỷ này có thể có giá trị 9 tỷ USD.

Lưu lượng tìm kiếm từ Safari cho Google có vẻ vẫn đủ ấn tượng để ông lớn này tiếp tục “nộp tiền” khủng cho Apple.
Theo Business Insider, Apple là một trong những kênh thâu tóm lưu lượng truy cập lớn nhất của Google – chiếm khoảng một nửa doanh thu trên di động của ông lớn công nghệ này. Vì thế, việc con số thương vụ tăng lên cũng không có gì lạ. Điều thú vị là Google có thể chấp nhận thương vụ này được đẩy đi xa đến mức nào. Sau tất cả, con số của năm nay đã tăng gấp ba lần so với năm ngoái. Business Insider thậm chí dự đoán trong vòng 12 tháng tới, số tiền mà Google phải trả có thể lên tới từ 12 tỷ đồng năm 2019.
Video đang HOT
Google chấp nhận chi bộn tiền để được là trình duyệt tìm kiếm mặc định trên iPhone và iPad, Apple vì sẽ có một nguồn thu đáng kể. Trong trường hợp Google từ chối hợp tác, một số ông lớn khác như Microsoft với sản phẩm Bing có thể sẽ sẵn lòng thế chân.
Nguồn: TGTT
Google trình làng công cụ tìm kiếm tập dữ liệu
Google đang áp dụng thử nghiệm công cụ tìm kiếm tập dữ liệu cho cộng đồng khoa học.
Công cụ tìm kiếm tập dữ liệu (Dataset Search) mới ra mắt của Google được kỳ vọng sẽ trở thành bạn đồng hành hữu hiệu với Google Scholar - công cụ tìm kiếm nghiên cứu và báo cáo học thuật hiện tại. Các viện nghiên cứu của các trường Đại học hay các tổ chức chính phủ khi công bố dữ liệu online sẽ cần thêm các metadata tags (các tags siêu dữ liệu) ở trang web để cung cấp mô tả về dữ liệu, bao gồm các thông tin về tác giả, thời gian công bố, cách thức dữ liệu được thu thập... Những thông tin này sau đó sẽ được sắp xếp lại theo thứ tự thành mục lục trên Dataset Search.
Phát biểu trong bài phỏng vấn của The Verge, Natasha Noy - một nhà khoa học nghiên cứu tại Google AI, người đã góp phần tạo nên Dataset Search - chia sẻ về mục tiêu hợp nhất 10.000 kho dữ liệu online: "Chúng tôi muốn dữ liệu được chia sẻ nhưng không bị di chuyển mà ở nguyên tại nơi đang lưu giữ".
Hiện tại, các tập dữ liệu công khai khá rời rạc. Mỗi lĩnh vực khoa học khác nhau lại có kho dữ liệu riêng. Điều này xảy ra tương tự với các kho dữ liệu của chính phủ hay chính quyền địa phương. Natasha Noy cho biết thêm: "Các nhà khoa học chia sẻ rằng họ biết chính xác nơi tìm kiếm dữ liệu cho lĩnh vực của họ nhưng không phải lúc nào cũng vậy. Khi bước ra khỏi lĩnh vực thế mạnh của mình, họ sẽ gặp khó khăn".
Noy lấy ví dụ về cuộc trò chuyện mới đây với một nhà nghiên cứu khí hậu. Cô than phiền với Noy rằng mình đang tìm kiếm tập dữ liệu về nhiệt độ đại dương cho một nghiên cứu sắp tới nhưng không thể thấy. Mãi đến khi tình cờ gặp một người đồng nghiệp ở một buổi hội thảo, cô mới biết dữ liệu mình cần được lưu giữ ở đâu. Cũng chỉ đến lúc đó cô mới có thể tiếp tục nghiên cứu của mình.
"Thậm chí đó không phải là một kho dữ liệu quý hiếm đặc biệt" - Noy nhấn mạnh - "Tập dữ liệu được ghi chép và lưu giữ ở một nơi khá nổi tiếng nhưng vẫn rất khó để tìm thấy".
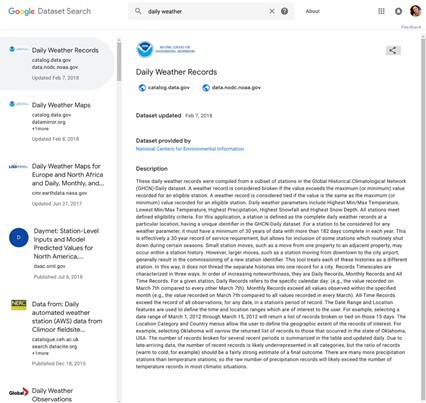
Ví dụ cho kết quả tìm kiếm về báo cáo thời tiết bằng Google Dataset Search
Trong lần ra mắt đầu tiên, Dataset Search sẽ bao gồm các chủ đề khoa học môi trường, khoa học xã hôi, dữ liệu chính phủ và các tập dữ liệu từ những viện tin tức như ProPublica. Tuy nhiên, nếu ứng dụng này trở nên phổ biến, lượng dữ liệu thu thập được sẽ tăng lên nhanh chóng bởi các viện nghiên cứu và các nhà khoa học sẽ tranh nhau chia sẻ thông tin của họ.
Jeni Tennison - CEO của Viện nghiên cứu Dữ liệu mở (ODI) - cho hay: "Tìm kiếm tập dữ liệu luôn khó khăn nhưng tôi hy vọng sự tham gia của Google sẽ giúp điều này trở nên dễ dàng hơn".
Theo Tennison, để tạo một công cụ tìm kiếm hiệu quả, cần phải nắm rõ hai điều. Thứ nhất là cần xây dựng một hệ thống thân thiện với người dùng. Thứ hai, cần tìm hiểu tâm lý hành vi hay ý định của người dùng khi họ gõ các cụm từ cụ thể để tìm kiếm. Google biết cách thực hiện cả hai điều trên.
Thật vậy, Tennison chia sẻ, lý tưởng nhất là Google sẽ công bố hướng dẫn cách vận hành của Dataset Search. Mặc dù các metadata tags sẽ công khai nguồn dữ liệu được công bố, các công cụ lấy dữ liệu tự động vẫn là một tiêu chuẩn mở, nghĩa là bất kỳ đối thủ nào, ví dụ như Bing hay Yandex, đều có thể phát triển một dịch vụ cạnh tranh. Công cụ tìm kiếm phát triển nhanh nhất chỉ khi một lượng người dùng đáng kể cùng chia sẻ dữ liệu của họ.
"Điều cơ bản và quan trọng nhất là phải hiểu cách mọi người tìm kiếm thông tin" - Tennison nói - "Nếu chúng ta muốn hiểu được cách mọi người tìm kiếm thông tin và khiến thông tin dễ dàng được tìm thấy, sẽ thật tuyệt nếu Google chia sẻ dữ liệu của chính họ về điều này".
Theo vtv
Công cụ tìm kiếm của Google tại Trung Quốc lưu trữ cả số điện thoại người dùng  Thông tin đáng quan ngại tiếp theo về dự án Dragonfly của Google tiếp tục được The Intercept đăng tải. Một số nguồn tin cho hay, nguyên mẫu công cụ tìm kiếm mà Google xây dựng tại Trung Quốc sẽ lưu trữ cả số điện thoại của người dùng. Tang web 256.com ghi lại năm 2008, trang web được Google mua lại từ...
Thông tin đáng quan ngại tiếp theo về dự án Dragonfly của Google tiếp tục được The Intercept đăng tải. Một số nguồn tin cho hay, nguyên mẫu công cụ tìm kiếm mà Google xây dựng tại Trung Quốc sẽ lưu trữ cả số điện thoại của người dùng. Tang web 256.com ghi lại năm 2008, trang web được Google mua lại từ...
Tin liên quan
 Google không tiết lộ kế hoạch phát triển công cụ tìm kiếm cho Trung Quốc
Google không tiết lộ kế hoạch phát triển công cụ tìm kiếm cho Trung Quốc 1.400 nhân viên Google ký tên vào lá thư phản đối kiểm duyệt công cụ tìm kiếm tại Trung Quốc
1.400 nhân viên Google ký tên vào lá thư phản đối kiểm duyệt công cụ tìm kiếm tại Trung Quốc Microsoft chuẩn bị hợp nhất công cụ tìm kiếm cho cả Windows 10, Office 365 và Bing
Microsoft chuẩn bị hợp nhất công cụ tìm kiếm cho cả Windows 10, Office 365 và Bing Chrome hạn chế dùng một mật khẩu cho nhiều trang web
Chrome hạn chế dùng một mật khẩu cho nhiều trang web Google Chrome tròn 10 tuổi và đang là trình duyệt thống trị
Google Chrome tròn 10 tuổi và đang là trình duyệt thống trị Trình duyệt Google Chrome tròn 10 năm tuổi
Trình duyệt Google Chrome tròn 10 năm tuổi
 Android Messages: Nhắn tin từ trình duyệt chưa bao giờ đơn giản đến vậy
Android Messages: Nhắn tin từ trình duyệt chưa bao giờ đơn giản đến vậy Google Chrome có thêm tính năng đơn giản nhưng vô cùng hữu dụng
Google Chrome có thêm tính năng đơn giản nhưng vô cùng hữu dụng Google chặn video tự động phát gây phiền toái trên Chrome
Google chặn video tự động phát gây phiền toái trên Chrome Phiên bản Chrome 64 giúp tải dữ liệu siêu tốc
Phiên bản Chrome 64 giúp tải dữ liệu siêu tốc Microsoft lý giải nguyên nhân khiến Edge ít có phần mở rộng
Microsoft lý giải nguyên nhân khiến Edge ít có phần mở rộng Thủ thuật duyệt web tốt hơn trên Microsoft Edge
Thủ thuật duyệt web tốt hơn trên Microsoft Edge Windows 11 chiếm bao nhiêu dung lượng ổ cứng?
Windows 11 chiếm bao nhiêu dung lượng ổ cứng? 5 điều nhà sản xuất smartphone không nói cho người mua
5 điều nhà sản xuất smartphone không nói cho người mua iPhone sẽ 'suy tàn' sau 10 năm nữa?
iPhone sẽ 'suy tàn' sau 10 năm nữa? One UI 7 đến với dòng Galaxy S21
One UI 7 đến với dòng Galaxy S21Tiêu điểm
 Nhiều mẫu điện thoại được kết nối Internet vệ tinh Starlink miễn phí
Nhiều mẫu điện thoại được kết nối Internet vệ tinh Starlink miễn phí Smartphone bình dân giảm hấp dẫn người Việt
Smartphone bình dân giảm hấp dẫn người Việt Tại sao phích cắm ba chấu lại quan trọng hơn chúng ta nghĩ?
Tại sao phích cắm ba chấu lại quan trọng hơn chúng ta nghĩ? Nhà mạng chạy đua xây dựng hạ tầng 5G
Nhà mạng chạy đua xây dựng hạ tầng 5G Giải pháp bảo mật nhận dạng mặt nạ silicon
Giải pháp bảo mật nhận dạng mặt nạ silicon
 TikTok tích hợp tính năng AI mới đầy 'ma thuật'
TikTok tích hợp tính năng AI mới đầy 'ma thuật' 5 ứng dụng Samsung người dùng Galaxy nên tải về do không cài sẵn
5 ứng dụng Samsung người dùng Galaxy nên tải về do không cài sẵnTin đang nóng


 Hoa hậu Thùy Tiên che giấu vai trò cổ đông trong phi vụ kẹo Kera thế nào?
Hoa hậu Thùy Tiên che giấu vai trò cổ đông trong phi vụ kẹo Kera thế nào?
 Tài xế cán chết nữ sinh 14 tuổi ở Vĩnh Long sắp xuất viện
Tài xế cán chết nữ sinh 14 tuổi ở Vĩnh Long sắp xuất viện Shipper ở TPHCM bị đánh gãy mũi từ mâu thuẫn đơn hàng 64.000 đồng
Shipper ở TPHCM bị đánh gãy mũi từ mâu thuẫn đơn hàng 64.000 đồng Nhà Dương Lâm có biến, Quỳnh Quỳnh lên live tuyên bố sốc, khui sự thật về chồng
Nhà Dương Lâm có biến, Quỳnh Quỳnh lên live tuyên bố sốc, khui sự thật về chồng
Tin mới nhất

Apple Intelligence 2.0: Loạt tính năng AI mới sắp "đổ bộ" lên iPhone

Đột phá AI: Con chip mới hứa hẹn cách mạng hóa nhiều lĩnh vực

Apple có thể loại bỏ trợ lý giọng nói Siri tại nhiều quốc gia

Tin công nghệ 19-5: iOS 19 có thể giúp iPhone tăng đáng kể thời lượng pin

Đưa ứng dụng AI vào quy trình thẩm định thuốc

Giải pháp xác thực định danh điện tử đạt chứng nhận quốc tế về sinh trắc học

Khi AI biết kiểm chứng thông tin: Bước tiến mới từ Viettel AI tại NAACL 2025

AirPods không còn là 'tai nghe' đơn thuần

Cân nhắc khi thử nghiệm bản beta của One UI 8

Bùng nổ trí tuệ nhân tạo làm tăng mạnh nhu cầu về NAND Flash

Dung lượng pin iPhone 17 Air là 'nỗi thất vọng lớn'

16 GB RAM không còn đủ cho game thủ
Có thể bạn quan tâm

HLV Alonso ra phán quyết về Modric
Sao thể thao
19:56:08 20/05/2025
Bỏ án tử hình với 4 tội danh: 'Nhân văn với tội phạm là độc ác với đồng bào'
Tin nổi bật
19:42:58 20/05/2025
Lại thêm 1 dự án khủng điêu đứng vì Thùy Tiên, netizen đồng loạt gọi tên một người
Hậu trường phim
19:36:45 20/05/2025
Cuộc sống vợ chồng của nam nghệ sĩ Việt lấy vợ hơn 3 tuổi, có 1 con riêng
Sao việt
19:29:03 20/05/2025
Vợ Quang Hải phẫu thuật thẩm mỹ bị nhầm Hòa Minzy, vợ Văn Hậu khoe đẹp tự nhiên
Netizen
19:23:02 20/05/2025
Muôn vẻ cách lên đồ với họa tiết kẻ sọc cho nàng sành điệu
Thời trang
18:05:34 20/05/2025
Shin Seung Ho xuất thân vệ sĩ Irene, 5 năm thăng cấp thành sao, visual cỡ nào?
Sao châu á
18:03:49 20/05/2025
Diddy lộ thỏa thuận bí mật, chi 100.000 USD 'bịt miệng', 2 ái nữ làm điều sốc?
Sao âu mỹ
18:03:40 20/05/2025
Châu Âu hoan nghênh Vatican sẵn sàng tổ chức đàm phán Nga - Ukraine
Thế giới
17:47:08 20/05/2025
Cà Mau: Khởi tố cựu Phó giám đốc Văn phòng Đăng ký đất đai H.Ngọc Hiển
Pháp luật
17:18:29 20/05/2025
 Sốc: Phát hiện thi thể sao nam nổi tiếng trong rừng, 2 tay bị trói chặt
Sốc: Phát hiện thi thể sao nam nổi tiếng trong rừng, 2 tay bị trói chặt

 Lời khai của Hoa hậu Thuỳ Tiên tại cơ quan điều tra
Lời khai của Hoa hậu Thuỳ Tiên tại cơ quan điều tra Cảnh sát công bố hình ảnh thực phẩm chức năng giả của vợ chồng dược sĩ Hà Nội
Cảnh sát công bố hình ảnh thực phẩm chức năng giả của vợ chồng dược sĩ Hà Nội Hoa hậu Nguyễn Thúc Thùy Tiên bị khởi tố
Hoa hậu Nguyễn Thúc Thùy Tiên bị khởi tố Khám xét nơi ở của hoa hậu Nguyễn Thúc Thuỳ Tiên
Khám xét nơi ở của hoa hậu Nguyễn Thúc Thuỳ Tiên Hoa hậu Thùy Tiên "lách" trách nhiệm vụ kẹo Kera như thế nào?
Hoa hậu Thùy Tiên "lách" trách nhiệm vụ kẹo Kera như thế nào? Người phụ nữ bị đâm tử vong giữa đường ở Bình Dương
Người phụ nữ bị đâm tử vong giữa đường ở Bình Dương Covid 19 đột biến chủng mới ở Thái Lan, TPHCM ghi nhận số ca nhiễm tăng nhanh
Covid 19 đột biến chủng mới ở Thái Lan, TPHCM ghi nhận số ca nhiễm tăng nhanh